为何智谱 AI 开源模型如此爆火?要知道虽然现在视频生成技术正逐步走向成熟,然而,仍未有一个开源的视频生成模型,能够满足商业级应用的要求。大家熟悉的 Sora、Gen-3 等都是闭源的。CogVideoX 的开源就好比 OpenAI 将 Sora 背后的模型开源,对广大研究者而言,意义重大。CogVideoX 开源模型包含多个不同尺寸大小的模型,目前智谱 AI 开源 CogVideoX-2B,它在 FP-16 精度下的推理仅需 18GB 显存,微调则只需要 40GB 显存,这意味着单张 4090 显卡即可进行推理,而单张 A6000 显卡即可完成微调。CogVideoX-2B 的提示词上限为 226 个 token,视频长度为 6 秒,帧率为 8 帧 / 秒,视频分辨率为 720*480。智谱 AI 为视频质量的提升预留了广阔的空间,期待开发者们在提示词优化、视频长度、帧率、分辨率、场景微调以及围绕视频的各类功能开发上贡献开源力量。性能更强参数量更大的模型正在路上,敬请关注与期待。模型
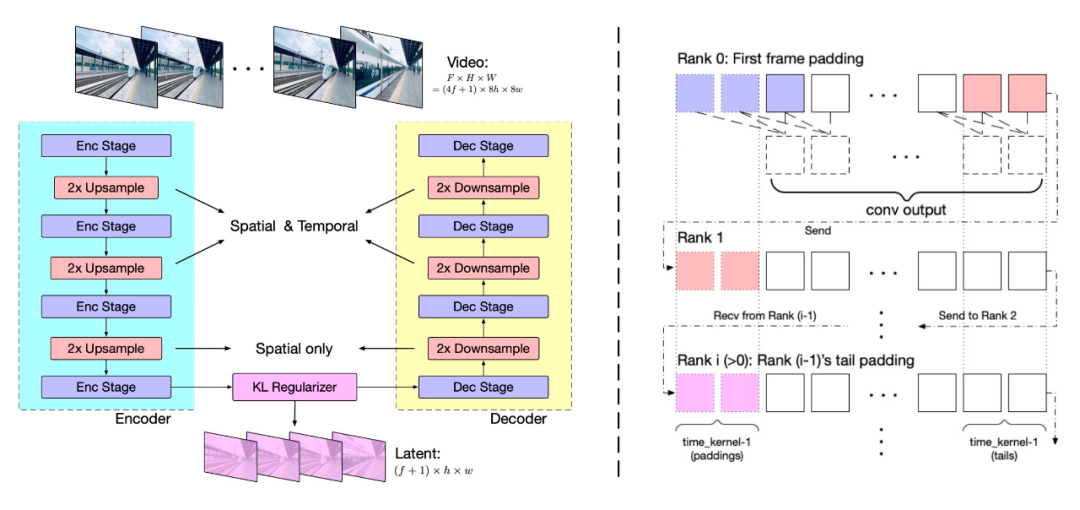
VAE视频数据因包含空间和时间信息,其数据量和计算负担远超图像数据。为应对此挑战,智谱提出了基于 3D 变分自编码器(3D VAE)的视频压缩方法。3D VAE 通过三维卷积同时压缩视频的空间和时间维度,实现了更高的压缩率和更好的重建质量。
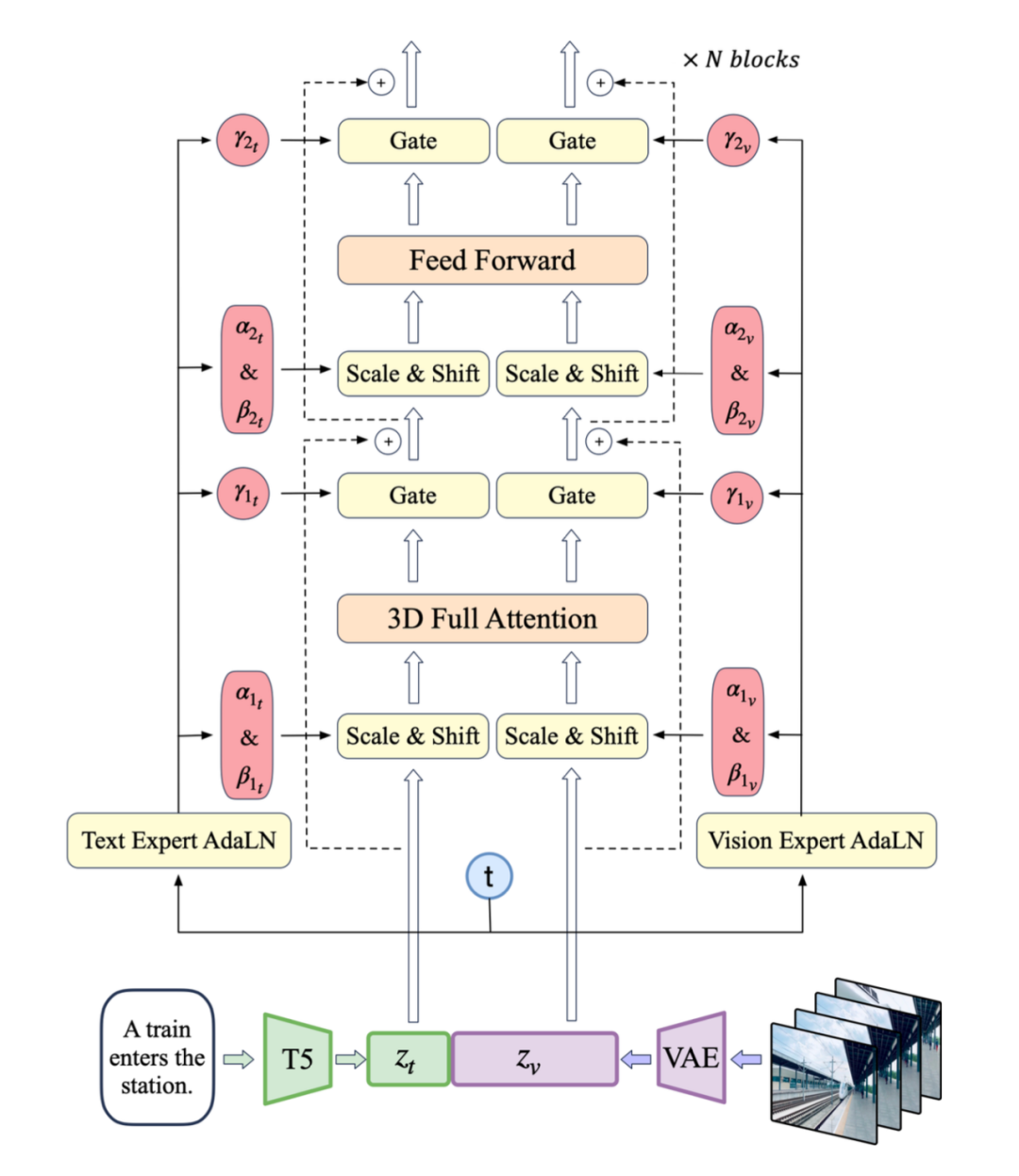
模型结构包括编码器、解码器和潜在空间正则化器,通过四个阶段的下采样和上采样实现压缩。时间因果卷积确保了信息的因果性,减少了通信开销。智谱采用上下文并行技术以适应大规模视频处理。实验中,智谱 AI 发现大分辨率编码易于泛化,而增加帧数则挑战较大。因此,智谱分两阶段训练模型:首先在较低帧率和小批量上训练,然后通过上下文并行在更高帧率上进行微调。训练损失函数结合了 L2 损失、LPIPS 感知损失和 3D 判别器的 GAN 损失。专家 Transformer智谱 AI 使用 VAE 的编码器将视频压缩至潜在空间,然后将潜在空间分割成块并展开成长的序列嵌入 z_vision。同时,智谱 AI 使用 T5,将文本输入编码为文本嵌入 z_text,然后将 z_text 和 z_vision 沿序列维度拼接。拼接后的嵌入被送入专家 Transformer 块堆栈中处理。最后,反向拼接嵌入来恢复原始潜在空间形状,并使用 VAE 进行解码以重建视频。
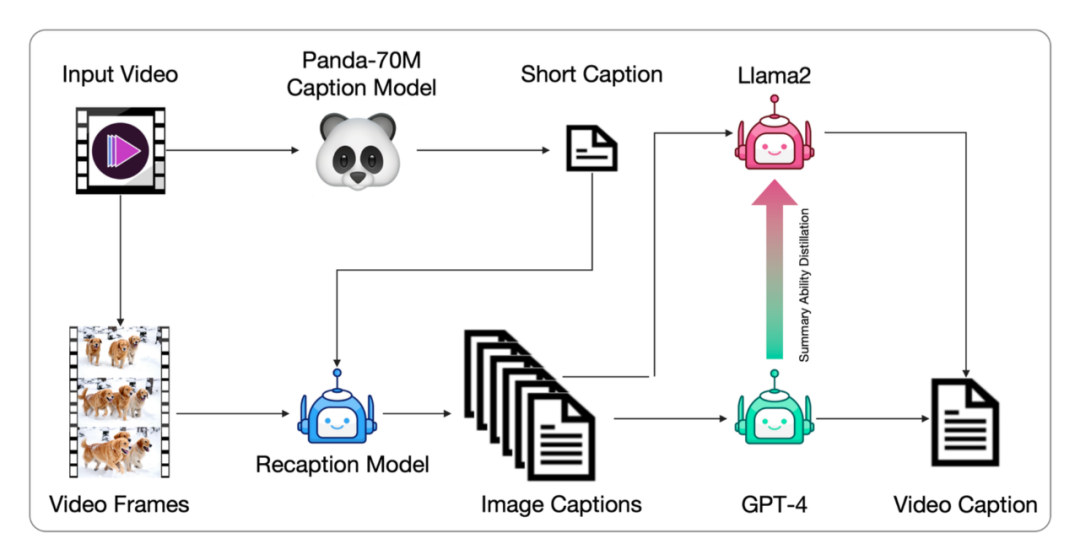
Data视频生成模型训练需筛选高质量视频数据,以学习真实世界动态。视频可能因人工编辑或拍摄问题而不准确。智谱 AI 开发了负面标签来识别和排除低质量视频,如过度编辑、运动不连贯、质量低下、讲座式、文本主导和屏幕噪音视频。通过 video-llama 训练的过滤器,智谱 AI 标注并筛选了 20,000 个视频数据点。同时,计算光流和美学分数,动态调整阈值,确保生成视频的质量。视频数据通常没有文本描述,需要转换为文本描述以供文本到视频模型训练。现有的视频字幕数据集字幕较短,无法全面描述视频内容。智谱 AI 提出了一种从图像字幕生成视频字幕的管道,并微调端到端的视频字幕模型以获得更密集的字幕。这种方法通过 Panda70M 模型生成简短字幕,使用 CogView3 模型生成密集图像字幕,然后使用 GPT-4 模型总结生成最终的短视频。智谱 AI 还微调了一个基于 CogVLM2-Video 和 Llama 3 的 CogVLM2-Caption 模型,使用密集字幕数据进行训练,以加速视频字幕生成过程。
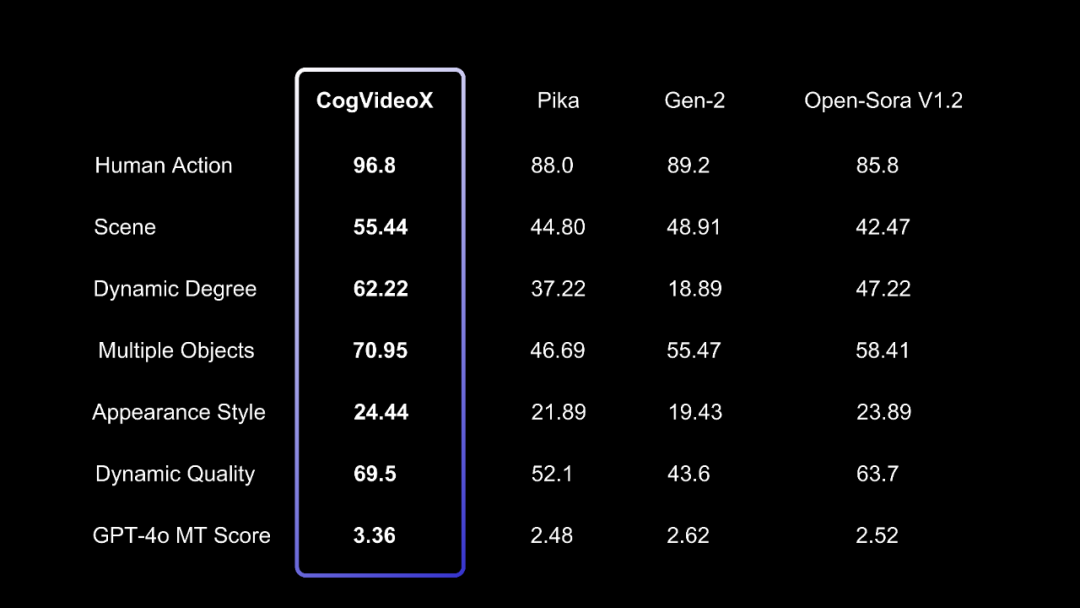
性能为了评估文本到视频生成的质量,智谱 AI 使用了 VBench 中的多个指标,如人类动作、场景、动态程度等。智谱 AI 还使用了两个额外的视频评估工具:Devil 中的 Dynamic Quality 和 Chrono-Magic 中的 GPT4o-MT Score,这些工具专注于视频的动态特性。如下表所示。
智谱 AI 已经验证了 scaling law 在视频生成方面的有效性,未来会在不断 scale up 数据规模和模型规模的同时,探究更具突破式创新的新型模型架构、更高效地压缩视频信息、更充分地融合文本和视频内容。最后,我们看看「清影」的效果。 提示语:「一艘精致的木制玩具船,桅杆和船帆雕刻精美,平稳地滑过一块模仿海浪的蓝色毛绒地毯。船体漆成浓郁的棕色,有小窗户。地毯柔软而有质感,提供了完美的背景,类似于广阔的海洋。船周围还有各种玩具和儿童用品,暗示着一个好玩的环境。这个场景捕捉到了童年的纯真和想象力,玩具船的旅程象征着在异想天开的室内环境中无尽的冒险。」提示语:「镜头跟随一辆装着黑色车顶行李架的白色老式 SUV,它在陡峭的山坡上沿着松树环绕的土路加速行驶,轮胎扬起尘土,阳光照射在沿着土路飞驰的 SUV 身上,为场景投下温暖的光芒。土路缓缓弯曲向远方延伸,看不到其他汽车或车辆。道路两旁的树木都是红杉,点缀着一片片绿植。从后面看,汽车轻松地顺着弯道行驶,让人觉得它正在崎岖的地形上行驶。土路周围是陡峭的山丘和山脉,头顶是湛蓝的天空,上面飘着薄薄的云彩。」提示语:「一片白雪皑皑的森林景观,一条土路穿过其中。道路两旁是被白雪覆盖的树木,地面也被白雪覆盖。阳光灿烂,营造出明亮而宁静的氛围。道路上空无一人,视频中看不到任何人或动物。视频的风格是自然风景拍摄,重点是白雪皑皑的森林之美和道路的宁静。」提示语:「鸡肉和青椒烤肉串在烧烤架上烧烤的特写。浅焦和淡烟。色彩鲜艳」