—- 本周为您解读 ③ 个值得细品的 AI & Robotics 业内要事 —-
1. Machine Unlearning 会是未来 LLM 的必需品吗?
为什么需要关注 Machine Unlearning?LLM 做 Unlearning会更难吗?LLM 公司能用 Unlearning 解决数据纠纷吗?Machine Unlearning 现在存在哪些局限?…
2. AI 搜索想要颠覆传统搜索,必须迈过哪些坎儿?
「AI 搜索赛道」近期涌进了哪些关键玩家?谷歌占据的九成搜索引擎市场份额是否会受到影响?国内外 AI 大厂、创企都是如何做「AI + 搜索」应用的?三种不同的路线有哪些差异?AI 搜索对比传统搜索在技术上有何不同?…
3. ICML 2024 透露了哪些技术趋势?
ICML 2024 与往年有何区别?ICML 今年的热度如何?ICML 今年论文热词有哪些?今年哪些研究领域备受关注?哪些 AI 研究者今年最为活跃?大会获奖论文有哪些?…
日期:8 月 2 日
事件:在人工智能疾速发展,LLM 应用开始被广泛应用的当下,全球各国政府对 AI 治理投入了越来越多的精力。在近期多国政府出台的 AI 治理法案中,政府对数据安全、伦理、隐私保护,以及 AI 技术与版权、用户权益等方面的约束条款愈发清晰。在此趋势下,可以用于保护用户隐私数据的 Machine Unlearning 技术也在引起越来越多的关注。
1、在过去的十年中,数据量的大幅增加和硬件性能的快速提升推动了机器学习技术的快速发展。伴随近几年 LLM 模型的发展则进一步带来了对各类数据的需求和消耗。
2、伴随人工智能技术所需的数据量不断增加,许多国家最近立法实施「被遗忘的权利(Right to Forgotten)」。
① 」被遗忘的权利「中显著的例子是欧盟的通用数据保护条例(GDPR)、加拿大的个人信息保护与电子文件法(PIPEDA)隐私立法和美国的加州消费者隐私法案(CCPA)。
② 根据这些法律,公司必须采取合理措施保证在请求时删除个人数据。
③ 截至近期,联合国即将进入执行的《人工智能法案》和美国多个州政府最近的立法行动也对人工智能在用户隐私、版权等方面的提出规范。
4、在此趋势下,Machine Unlearning 技术受到越来越多的关注。
① 由于企业会利用用户数据训练模型。当用户行使「被遗忘的权利」,要求公司停止使用其数据,如果每次都要重新训练模型以响应用户的要求,将对企业造成巨大的开销和损失。
② 从技术层面看,Machine Unlearning 领域的研究不仅限于隐私保护,还包括分析不同数据对模型收敛时所贡献的梯度。这种分析有助于实现更精准的去学习,同时也能增强模型对噪声数据的检测能力(Noisy Data Detection)。
LLM 要如何用 Unlearning 进行数字遗忘?
罗维拉-伊-维尔吉利大学、CYBERCAT 和华为等机构的研究者在综述《Digital Forgetting in Large Language Models: A Survey of Unlearning Methods》讨论了在 LLM 中的数字遗忘问题,并梳理了 LLM 中所涉及的 Unlearning 方法进行梳理和对比。这些方法与广义 Machine Unlearning 的方法既有交叉,也有区别。
1、该工作围绕自 2022 年 11 月 ChatGPT 发布以来,LLM 的广泛应用和引发的问题,以数字遗忘为核心解决方案,阐述了包含 Machine Unlearning 在解决 LLM 对市场、隐私、版权等方面的影响。
① 该工作指出,LLM 的普及引发了有关模型与社会价值观和法治的一致性许多问题。
② 这些问题包括各类 LLM 对劳动力市场的影响、对个人隐私权的影响、对版权法的影响、对加剧偏见和歧视的影响,以及可能生成有害内容,包括可能被用来造成伤害的内容。
2、该工主要围绕数字遗忘技术展开讨论,其目标是给定一个具有不期望知识或行为的模型,经过数字遗忘处理后获得一个新模型,在该模型中不再存在检测到的问题。
② 有效的数字遗忘机制必须满足潜在冲突的要求包含:遗忘的有效性,即新模型遗忘不期望知识/行为的效果(无论是通过正式保证还是通过经验评估);模型在期望任务上的保留性能;以及遗忘过程的时效性和可扩展性。
3、该工作讨论了 LLM 的背景,描述了数字遗忘的动机、类型和期望属性,并介绍了 LLMs 中数字遗忘的方法,其中 Unlearning 的方法盘点核心。
4、该工作将适用于 LLM 的 Unlearning 方法分为四个大类,分别是全局权重修改、局部权重修改、架构修改和输入/输出修改方法。
① 全局权重修改(Global Weight Modification)指修改模型的所有参数以实现遗忘,其代表性方法包含数据分片(Data sharding)、梯度上升(Gradient ascent)、知识蒸馏(KD)、Generic alternatives 和强化学习。
② 局部权重修改(Local Weight Modification)指今修改模型中与遗忘目标相关的特定参数,其代表性方法为局部重训练(local retraining)、任务向量调整(task vector)和直接修改(Direct modification)
③ 架构修改(Architectur Modification)指在模型结构中添加新的层或应用线性变换,其代表性方法涉及额外的课学习层和线性变换。
④ 输入/输出修改(Input/output Modification)指在 LLM 的输入或输出层面上进行修改,但不改变模型内部参数,其代表性方法包含输入操纵和信息检索。
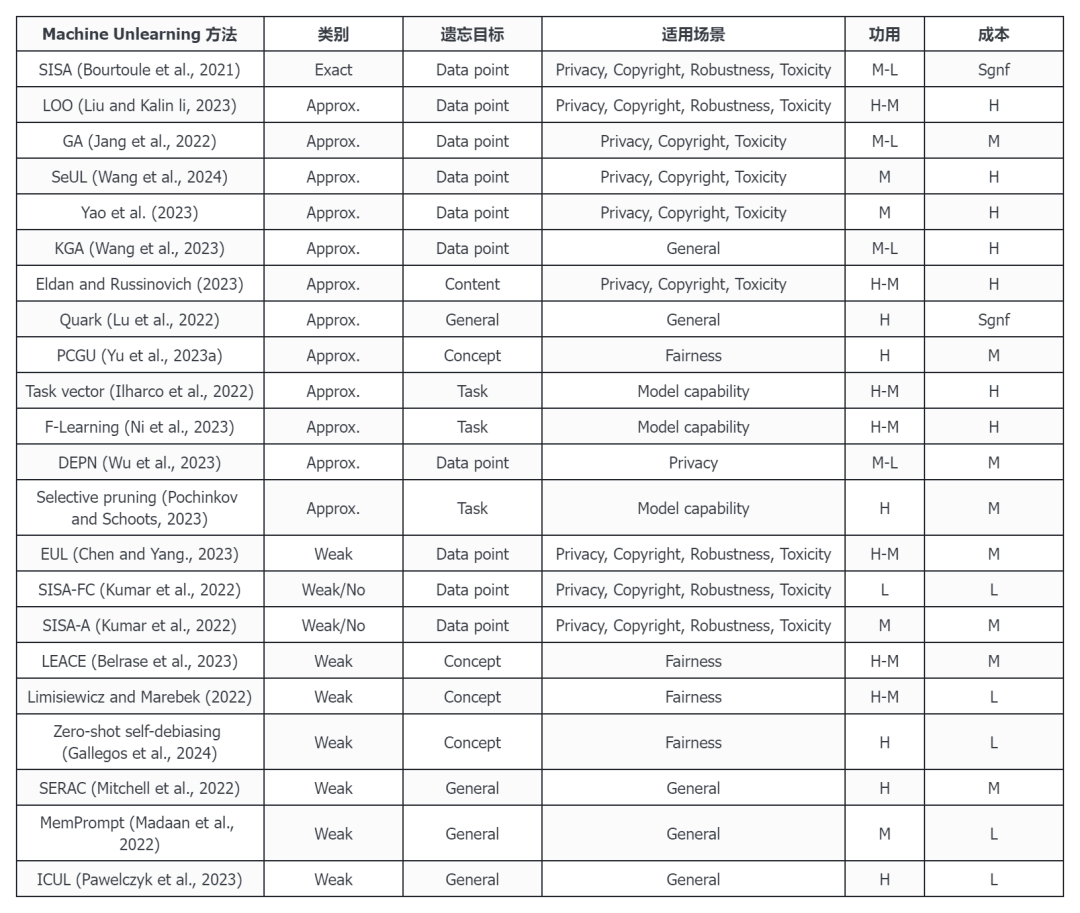
5、研究者对适用于 LLM 的 Unlearning 方法展开了一系列评估,包括所使用的数据集、模型和度量标准。
① 其分析的度量标准含三方面:模型是否有效地遗忘了目标知识;模型是否保留了其余的能力;遗忘过程的计算成本。
表 :LLM Unlearning 方法对比,L、M 和 H 分别表示低、中和高,Sgnf 表示极高。
LLM 中的 Unlearning 方法还有哪些难题亟待解决?
Machine Unlearning 作为一项新技术,在人工智能与大模型领域正在逐渐收到重视。然而,大多数现有方法仍存在不同层面的局限,而仍在发展中的 LLM 的部分特性则为 Machine Unlearning 带来了更多挑战。在。2023 年 10 月发布的综述《Large Language Model Unlearning》、2024 年的综述《《Digital Forgetting in Large Language Models: A Survey of Unlearning Methods》以及近期的工作中均指出了 Unlearning 方法当前面临的问题。
1、在 2023 年 10 月发布的综述《Large Language Model Unlearning》中,研究者重点关注了如何在 LLM 中进行 Unlearning。对比传统的分类模型,Unlearning 在 LLM 中面临着一些不同的挑战[7] :
① LLMs 的输出空间远大于标签类别,其带来的可能的结果数量远超传统分类模型。
② LLMs 的规模巨大,任何昂贵的 Unlearning 方法在 LLMs 上都不切实际。
③ LLMs 的训练语料库庞大且通常无法访问,难以获取训练数据的真实模型和行为,使得评估也变得困难。
④ 现有的 Unlearning 方法大多几种于分类模型上,但它们在计算成本和适用性的局限性使其无法直接应用于 LLMs。即便是流行的 RLHF 业存在极大的资源消耗,需要收集大量高质量的人类编写的样本。
2、《数字遗忘》的研究者指出,LLM 中,Machine Unlearning 是一个新的热点,但尚未成熟的研究领域。[6]
① 现有的许多 Unlearning 方法计算成本过高。其中,数据分片和梯度上升等涉及全局权重修改的方法需要大量的计算资源,这种 Unlearning 方式这不仅延长了遗忘过程的时间,还增加了实现遗忘所需的硬件成本。
② 由于在训练和推理过程中,模型需要占用大量的内存,LLM 尤为明显。因此,的 Unlearning 方法在处理大规模模型时可能会遇到内存限制。
③ 现有的 Unlearning 方法往往无法完全删除模型中的不期望知识。一些方法可能只是减少了这些知识的影响,而不是完全消除。这可能导致模型在某些情况下仍然表现出不期望的行为。
④ 泛化能力不足:一些 Unlearning 方法在处理特定任务或领域时表现良好,但在其他任务或领域上效果不佳。这意味着这些方法可能缺乏足够的泛化能力,无法在所有情况下都有效。
⑤ 某些 Unlearning 方法可能只适用于特定的数据类型或模型架构。同样的,一些 Unlearning 方法在处理特定任务或领域时表现良好,但在其他任务或领域上效果不佳。
⑥ 由于 LLM 的输出空间巨大,评估 Unlearning 方法的成功与否非常困难。现有的评估指标和方法可能无法充分捕捉到 Unlearning 方法的实际效果。
3、华盛顿大学、普林斯顿大学和南加州大学等机构的研究者在近期发布的《MUSE》论文中提出了面向 LLM 中 Unlearning 方法的综合评估基准。他们评估发现绝大多数 Unlearning 算法会降低模型的一般效用,且不能持续地适应连续的遗忘请求或大规模内容删除。[8]



