


大模型展现出了卓越的指令跟从和任务泛化的能力,这种独特的能力源自 LLMs 在训练中使用了指令跟随数据以及人类反馈强化学习(RLHF)。在 RLHF 训练范式中,奖励模型根据排名比较数据与人类偏好对齐。这增强了 LLMs 与人类价值观的对齐,从而生成更好地帮助人类并遵守人类价值观的回应。
近日,第一届大模型顶会 COLM 刚刚公布接收结果,其中一项高分工作分析了 LLM 作为文本评估器时难以避免和纠正的分数偏见问题,并提出了将评估问题转换成偏好排序问题,从而设计了 PairS 算法,一个可以从成对偏好(pairwise preference)中搜索和排序的算法。通过利用不确定性和 LLM 传递性(transitivity)的假设,PairS 可以给出高效,准确的偏好排序,并在多个测试集上展现出和人类判断更高的一致性。

-
论文链接: https://arxiv.org/abs/2403.16950
-
论文标题:Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators
-
Github 地址: https://github.com/cambridgeltl/PairS
用大模型评估有什么问题?
最近大量的工作展示了 LLMs 在评估文本质量上的出色表现,形成了一种无需参考的生成任务评估新范式,避免了昂贵的人类标注成本。然而,LLM 评估器(evaluator)对提示(prompt)设计高度敏感,甚至会受到多种偏见的影响,包括位置偏见、冗长偏见和上下文偏见。这些偏见阻碍了 LLM 评估器的公平和可信,导致与人类判断的不一致和不对齐。
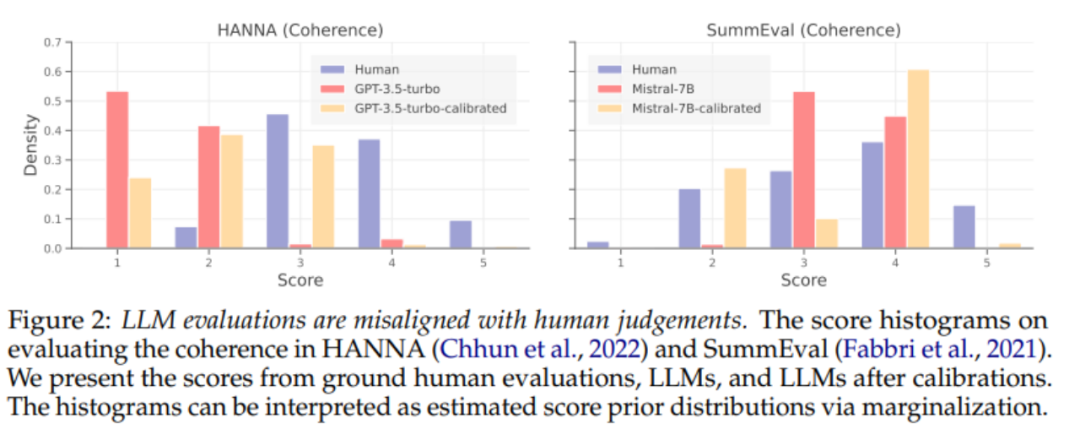
为了减少 LLMs 的偏见预测,之前的工作开发了校准技术(calibration)以减少 LLM 预测中的偏见。我们先对校准技术在对齐单点(pointwise) LLM 评估器的有效性进行了系统分析。如上图 2 所示,即使提供了监督数据,现有的校准方法仍然不能很好的对齐 LLM 评估器。
如公式 1 所示,我们认为评估不对齐的主要原因并非 LLM 评估分数分布的先验具有偏见(biased priors over evaluation score distribution),而是评估标准(evaluation standard)的错位,即 LLM 评估器的似然(likelihood)。我们认为做成对(pairwise)评估时,LLM 评估器会与人类有更一致的评价标准,因此,我们探索了一种新的 LLM 评估范式,以促进更对齐的判断。

RLHF 带来的启发
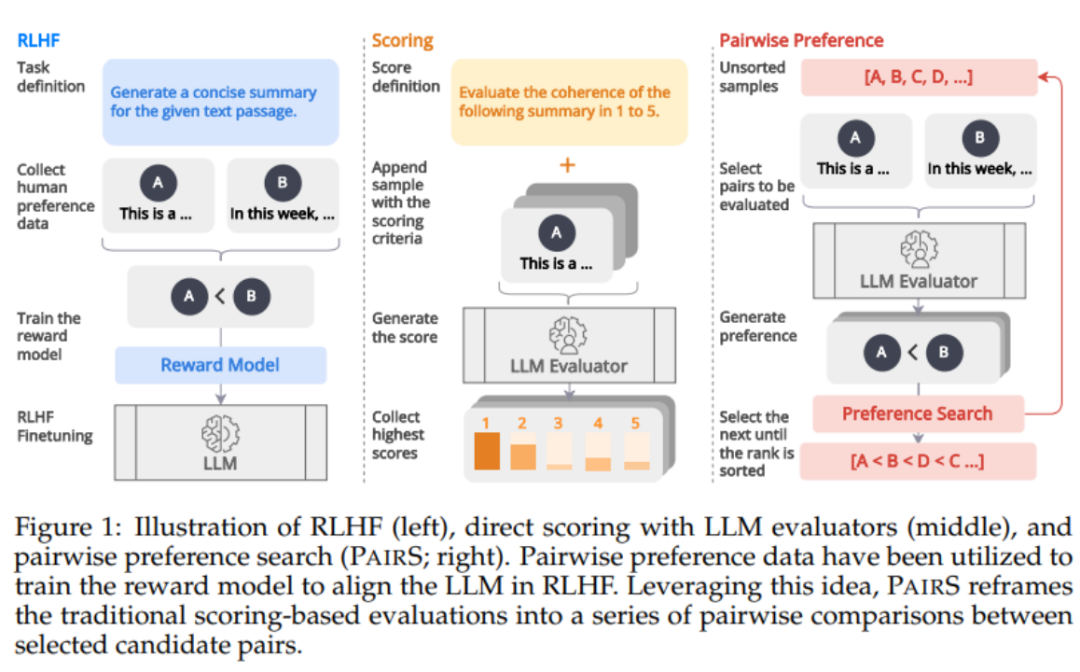
如下图 1 所示,受到 RLHF 中通过偏好数据对奖励模型进行对齐的启发,我们认为 LLM 评估器可以通过生成偏好排序(preference ranking)来得到更和人类对齐的预测。最近已有一些工作开始通过让 LLM 进行成对比较(pairwise comparison)来得到偏好排序。然而,评估偏好排序的复杂性和可扩展性在很大程度上被忽视了。它们忽略了传递性假设(transitivity assumption),使得比较次数的复杂度为 O (N^2),让评估过程变得昂贵而不可行。
PairS:高效偏好搜索算法
在本工作中,我们提出了两种成对偏好搜索算法(PairS-greedy 和 PairS-beam)。PairS-greedy 是基于完全的传递性假设和合并排序(merge sort)的算法,只需要通过 O (NlogN) 的复杂度就可以得到全局的偏好排序。传递性假设是指,比如对于 3 个候选项,LLM 总是有如果 A≻B 以及 B≻C,则 A≻C。在这个假设下我们可以直接用传统的排序算法从成对偏好中获得偏好排序。
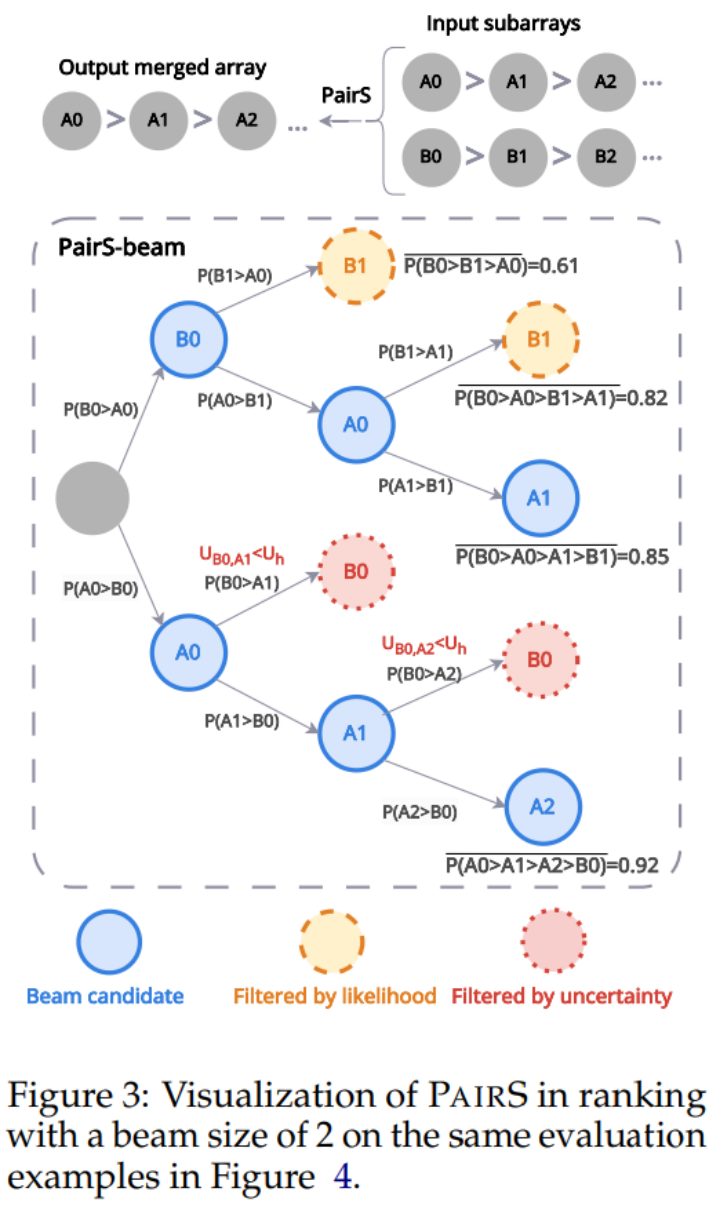
但是 LLM 并不具有完美的传递性,所以我们又设计了 PairS-beam 算法。在更宽松传递性假设下,我们推导并化简了偏好排序的似然函数(likelihood function)。PairS-beam 在合并排序算法的每一次的合并操作(merge operation)中按似然值做集束搜索,并通过偏好的不确定性(uncertainty)来减枝成对比较的空间的搜索方法。PairS-beam 可以调整对比复杂度和排序质量, 高效的给出偏好排序的最大似然估计(MLE)。在下图 3 中我们展示了一个 PairS-beam 如何做合并操作的例子。
实验结果
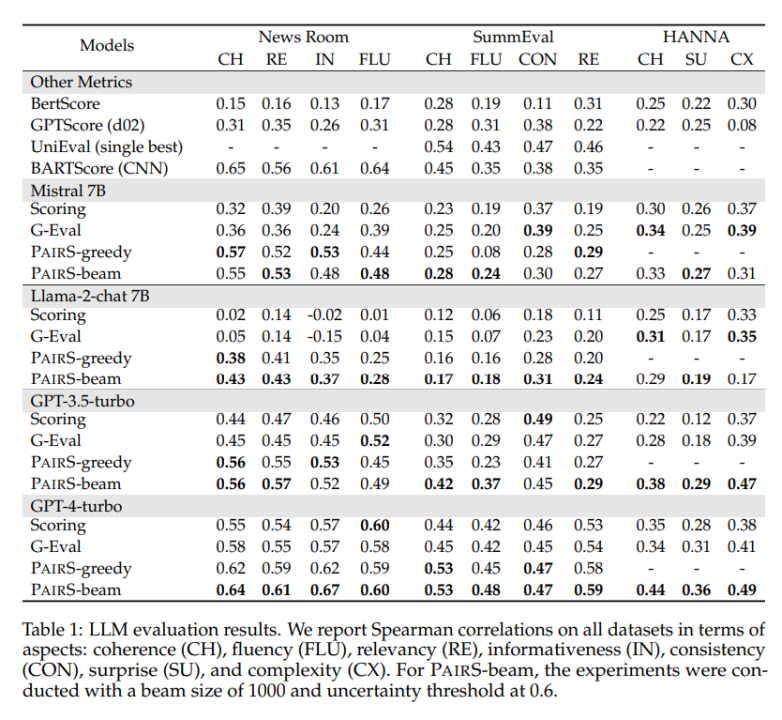
我们在多个具有代表性的数据集上进行了测试,包括闭合式生成的缩写任务NewsRoom 和 SummEval,和开放式的故事生成任务HANNA,并对比了多个 LLM 单点评估的基线方法,包括无监督的 direct scoring, G-Eval, GPTScore 和有监督训练过的 UniEval 以及 BARTScore。如下表 1 所示,PairS 在每个任务上和他们相比都有着和人类评分更高的一致性。GPT-4-turbo 更是能达到 SOTA 的效果。
在文章中,我们还对比了两种偏好排序的基线方法,win rate 和 ELO rating。PairS 可以仅用约 30% 的对比次数就能达到他们同样质量的偏好排序。论文还提供了更多关于如何使用成对偏好来量化计算 LLM 评估器的传递性,以及成对评估器如何在校准中受益的见解。
