大语言模型 (LLM) 是如何解数学题的?是通过模板记忆,还是真的学会了推理思维?模型的心算过程是怎样的?能学会怎样的推理技能?与人类相同,还是超越了人类?只学一种类型的数学题,是会对通用智能的发展产生帮助?LLM 为什么会犯推理错误?多大多深的 LLM 才能做推理?

论文地址:https://arxiv.org/abs/2407.20311
近日,来自 Meta FAIR、CMU 和 MBZUAI 的叶添、徐子诚、李远志、朱泽园四人团队最新公布 arXiv 论文《语言模型物理学 Part 2.1:小学数学与隐藏的推理过程》用可控实验,巧妙地回答上述问题。推特网友 @xlr8harder 评价,「这一结果将一劳永逸地平息关于 LLM 是否具有推理能力,或者只是随机鹦鹉的争论。」
编者注:《语言模型物理学》全系列受邀于 7 月 22 日在 ICML 2024 国际机器学习顶级大会上进行了两小时的专题报告,反响热烈,据悉现场掌声不断。这里为大家呈现系列中的 Part 2.1。
 图 1
图 1
论文详解
首先,根据本系列的惯例,作者认为不应通过与 GPT-4 等大模型对话来猜测其思维方式,这类似于动物行为学,虽可行但不够严谨,无法科学地揭示 GPT-4 的内心思考过程。
此外,从数据角度看,只有完全访问模型的预训练集(pretrain data),才能明确哪些题目是模型见过的,哪些是通过推理学会的。即使模型在 GSM8k(包含 8000 道小学数学题的基准测试集)上获得高分,也难以判断它是否见过这些题目的变体(如不同语言或 GPT-4 改写后的变体)。
为此,作者创建了 iGSM,一个人工合成的、模拟小学数学级别的思维题集,并让模型从零开始在 iGSM 上预训练,以控制模型接触的问题类别。值得注意的是,iGSM 不包含常识信息,只包含 mod 23 范围内的加减乘,并且所有计算都使用 CoT 逐步进行。通过 iGSM,可进行可控实验,专门研究模型的推理能力,而忽略了其他因素(如大整数运算)。图 2 展示了一个简单的例题。
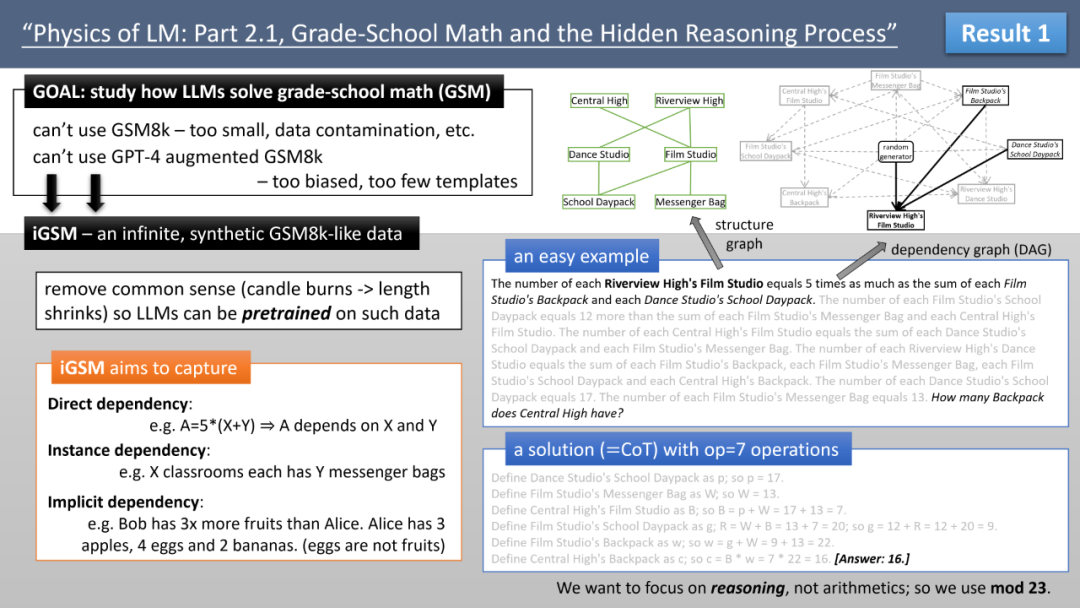 图 2
图 2
通过这个数据集,作者首先测试了 GPT2(RoPE 版)的表现。用 op 代表解题所需的数学运算步数,作者发现,当在 op≤21 的题目上进行训练时,模型不仅能达到 99% 正确率,还能在更高难度的题目(如 op=32)上保持 83% 的正确率(见图 3)。这表明模型学会了某种推理技能,毕竟它从未见过 op>21 的题。(顺带一提,GPT-4o 在该数据集上仅能应对 op=10 的题目,超过这个难度就如同盲猜,文末我们会讨论这个问题。)
那模型究竟学会了怎样的推理技能呢?解决 iGSM 的数学题至少有两种思路。一种是作者称为「0 级推理」,即「暴力计算能算则算」。由于题目中的变量可能存在复杂的依赖关系,有些可以直接计算,有些则需要先算出其他变量 —— 譬如小张比小王多 3 倍的水果,那么就要先算出小王有多少苹果、梨子并求和,才可以开始计算小张的水果数。「0 级推理」就是尽可能枚举所有变量,每次随机找到一个可计算的变量,算出结果并继续。
与之对应的是「1 级推理」:通过拓扑排序,从问题开始反推,确定哪些变量需要计算,然后从叶子节点开始向上计算,力求「最短解答」。常见的数学题解通常采用 1 级推理,不会去计算「不必要的变量」。例如小张比小王多 3 倍的水果,问小张有多少水果,那小李的苹果数就是不必要的变量,而小王的苹果、梨子数都是必要的。
如图 3 所示,作者发现,GPT-2 可以学会 1 级推理,几乎每次都给出最短解答。这非常不简单!因为在模型生成第一句话之前,必须已经在脑海中完成了整个拓扑排序 —— 否则它怎么知道哪个变量是不必要的?如果模型一开始就生成了「小李的苹果有 7 个」,那就无法回头,得不到最短解答。
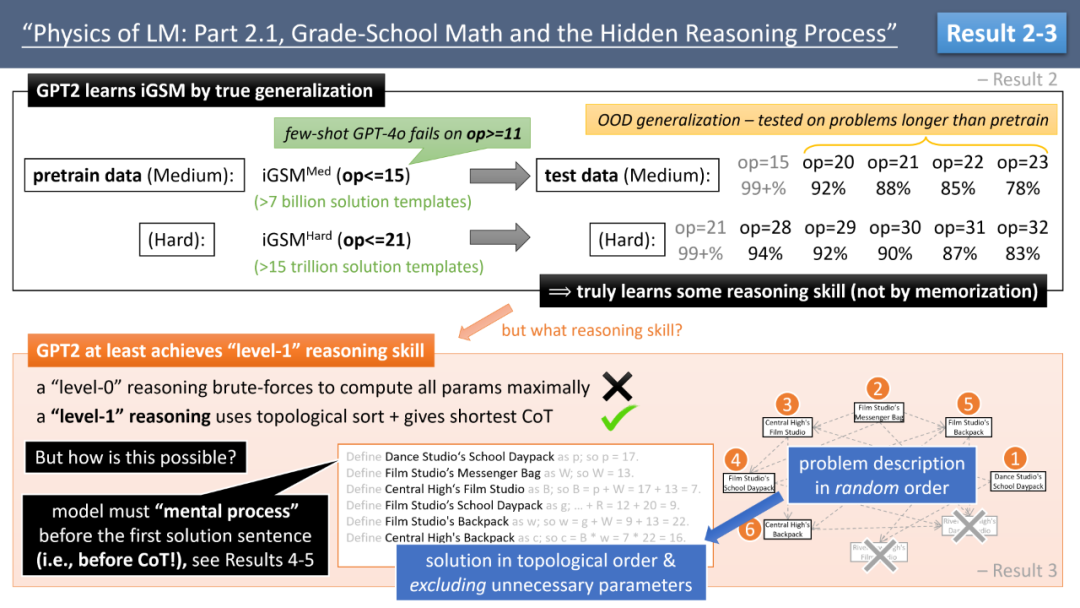 图 3
图 3
那么,模型是如何学会「1 级推理」的?为此,作者对模型的内部参数进行了探针 probing 研究(见图 4)。结论显示(具体探针方法详见论文),在模型生成第一句话之前,它已经通过心算确定了哪些变量 A 是「必要的」(nece (A)=True)。同时,模型在说每句话之后,也心算出了接下来所有「可计算的」的变量 A(cannext (A)=True)。因此,模型只需对 nece 和 cannext 不断进行逻辑与(AND)运算,就能从叶子节点开始,一步步给出完整的计算过程。
值得注意的是,这些复杂的心算能力并没有显现在训练集中。模型只接触过 iGSM 数据,只见过「语言」部分(题目和答案),但它却自主学会了类似人类的思维过程(mental process),并得出了最优解!换言之,这项研究反驳了我们一周前在《语言≠思维,大模型学不了推理:一篇 Nature 让 AI 社区炸锅了》中的报道,用科学方法证明了大模型通过语言确实能学会思维。
更神奇的是,模型学到的不止如此。在图 4 中,作者还发现模型会心算许多对解题无用的信息。比如,在变量关系刚被描述完,甚至在问题尚未提出之前,模型已经知道任意两个变量 A 和 B 之间是否存在递归依赖 —— 即使这些变量与解题无关。对人类来说,我们通常会从问题开始反推,忽略不必要的变量,而 GPT-2 这样的语言模型则会将整个关系图梳理一遍,以应对将来可能被问及的任何问题。作者将这种能力称为「2 级推理」。
虽然「2 级推理」对解题不必须,但它确实是一种更通用的技能。模型利用并行能力,对信息进行大量因果梳理。这一能力是语言模型在学习解题中自行掌握的,没有人 (数据) 教过它这么做。作者猜测,这或许是通用人工智能(AGI)中「通用」一词的潜在来源,即语言模型可以超越数据集所教的技能,学会更为通用的能力。
 图 4
图 4
接下来,作者研究了模型为何会犯错。总结来看,在 iGSM 数据集上,模型几乎只会犯两类错误:一是计算不必要的变量,二是计算当前不可算的变量,如图 5 所示。
对于前者,作者发现,如果模型在生成答案之前就心算出错,误认为某个变量 A 是 「必要的」(nece (A)=True),那么模型在生成答案时很可能会对 A 强行计算,从而产生非最短解答。这一发现非常有趣,它表明许多错误是系统性的,在生成第一个 token 之前,模型还没张嘴就可以确信它会犯错(通过探针的方法)。这类错误与模型生成过程中的随机性或 beam search 无关。
至于后者,作者也将其归因于心算错误,并将用一整篇的后续 Part 2.2 论文,来针对性提高模型的心算能力,以最终提高解题正确率。该论文尚未发布,我们会在公众号中继续关注并报道。
 图 5
图 5
下一个结论是,作者反驳了大模型缩放定律(scaling law)中强调的「唯大独尊」,即模型的表现只与参数数量相关,而与宽度或深度无关。这一观点最早由 OpenAI 的缩放定律论文提出,并在后续几乎所有研究中得到遵循。
作者通过 iGSM 数据集进行了一个可控实验,如图 6 所示。通过对比更小更深的模型与更大更宽的模型,发现对于解决 iGSM 中的数学题,模型的深度显然比宽度更为重要。例如,一个 20 层、9 个 head 的模型,表现远好于 4 层、30 个 head 的模型,尽管后者有两倍的参数。
更进一步,作者发现对深度的依赖源于模型心算的复杂性。通过对模型不同深度的探针研究,作者发现,对于那些与问题较远的变量 A,心算 nece (A) 往往需要更多层数。具体来说,若变量 A 与问题变量的距离为 t,则需要进行 t 步心算才能知道 nece (A)=True。t 越大,模型所需的层数也越多,如图 6 所示。
作者强调,模型对深度的依赖无法通过思维链(Chain-of-Thought, CoT)来抵消。事实上,iGSM 中的数学题解已经尽可能地使用了 CoT,即所有计算都被拆解为一步一步。即便如此,模型仍需要通过心算来规划 CoT 的第一步该算什么 —— 这个心算过程可能依然需要多个步骤。这解释了模型对深度依赖的原因。
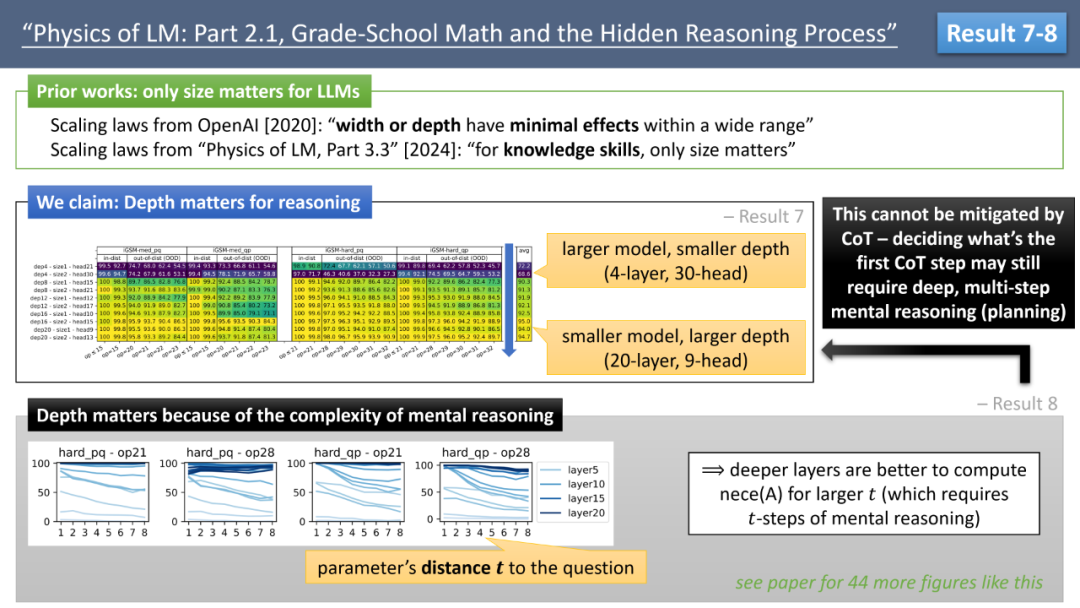 图 6
图 6
综上所述,与 99% 以上的研究 LLM 行为过程(behavior process)的论文不同,本文作者另辟蹊径,揭示了 LLM 在解决数学问题时的心理过程(mental process),为理解 LLM 的智能提供了新的视角。
文章最后作者指出,即便是 GPT-4,在 iGSM 数据集上也只能进行最多 10 步的推理。这表明,即使是当前最强的模型,利用了据称所有的互联网数据,仍无法精准地完成超过 10 步推理。这暗示现有大模型使用的预训练数据集(pretrain data)可能还有很大的改进空间。通过本文的方法,建立人工合成数据来增强模型的推理能力以及信息梳理能力,或许是一种新的可能。



