


研究人员提出了一种新颖的多步误差最小化(MEM)方法,用于生成多模态不可学习样本,以保护个人数据不被多模态对比学习模型滥用。通过优化图像噪声和文本触发器,MEM方法有效地误导模型,降低其对隐私数据的学习能力,并在不同模型间展现出强大的可迁移性。
多模态对比学习(如CLIP)通过从互联网上抓取的数百万个图像-字幕对中学习,在零样本分类方面取得了显著进展。
然而,这种依赖带来了隐私风险,因为黑客可能会未经授权地利用图像-文本数据进行模型训练,其中可能包括个人和隐私敏感信息。
最近的工作提出通过向训练图像添加难以察觉的扰动来生成不可学习样本(Unlearnable Examples),可以建立带有保护的捷径.
然而,这些方法是为单模态分类任务设计的,在多模态对比学习中仍未得到充分探索。本文首通过评估现有方法在图像-标题对上的性能来探索这一背景,由于在该场景中缺乏标签,之前的无法有效地推广到多模态数据,并且在建立捷径方面的效果有限。
在本文中提出了多步误差最小化(MEM),这是一种用于生成多模态不可学习样本的新颖优化过程。它扩展了误差最小化(EM)框架,以优化图像噪声和额外的文本触发器,从而扩大了优化空间,并有效地误导模型学习噪声特征和文本触发器之间的捷径。

论文链接: https://arxiv.org/abs/2407.16307
代码链接: https://github.com/thinwayliu/Multimodal-Unlearnable-Examples
具体来说,采用投影梯度下降来解决噪声最小化问题,并使用HotFlip方法来近似梯度和替换单词,以找到最佳的文本触发器。
大量实验证明了方法的有效性,保护后的检索结果几乎是随机猜测的一半,并且它在不同模型之间具有高度的迁移性。本篇工作的论文和代码均已开源。
研究背景
近年来,随着多模态学习的兴起,研究者们对结合文本、图像和音频等多种数据类型的模型产生了浓厚的兴趣。
其中,多模态对比学习成为了这一领域的重要方法,如CLIP和ALIGN等模型利用对比损失训练,以增强图像和文本的相关性,进而减少人工标注的需求,并展示了在图像分类、生成等任务中的潜力。
然而,这些模型的训练依赖于大量的多模态数据,这些数据常常来自公开的数据集,如CC12M、YFCC100M和LAION5B,但这些数据集可能仍然不足,且可能包含大量敏感的个人信息,引发了对隐私泄露的担忧。
我们考虑了一个专注于生成多模态不可学习样本以应对与多模态对比学习相关的隐私风险的场景。在这种场景下,我们专注于图像-文本对作为代表性的多模态数据集。假设用户经常在社交媒体平台(如Facebook)上分享带有文本的个人照片,包括一些私人身份信息,如面孔、姓名、电话号码和地址。
目前,黑客试图从互联网上收集大量此类图像-文本对,并利用多模态对比学习技术训练或微调大模型,如图1的左半部分所示。
这些模型无意中捕获了用户的私人信息和面部特征,导致潜在的隐私泄露。保护者旨在通过对多模态数据进行不可学习的方法来防止这些敏感数据被未经授权利用。这些方法使在这种多模态不可学习样本上训练的模型无法访问用户的隐私特征,同时不妨碍用户在发布图像和文本后的社交互动,如图1的右半部分所示。
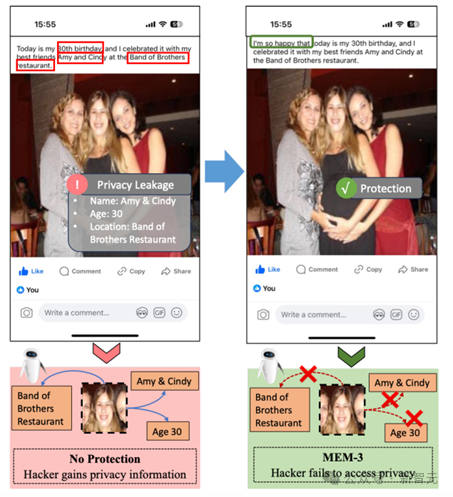
图1:Facebook上的帖子无意中会泄露了个人信息(如图左),但利用多模态不可学习样本可以保护数据可以防止未经授权的模型访问私人特征(如图右)
动机
最近的研究致力于通过不可学习样本(Unlearnable Examples)来防止图像分类中的数据未经授权使用。这些方法通过对数据施加细微扰动来阻碍模型学习图像特征,也被称为可用性攻击(availability attacks)或无差别的中毒攻击(indiscriminate poisoning attacks)。
它主要分为无代理模型攻击和基于代理模型的攻击,其中无代理模型攻击通过在像素级别生成噪声,而基于代理模型的攻击则通过代理模型生成特征级别的噪声。
然而,所有用于分类的无代理模型方法在多模态场景下都无法生成图像噪声,因为这些方法旨在为与某个特定类别相关的图像找到一系列特定的噪声模式,而图像-文本对数据中没有标签。
因此,只有基于代理模型的方法可以应用,我们扩展了两种典型的方法来生成不可学习的多模态示例(EM和UAP)。
The Error-minimizing Noise(EM)方法:
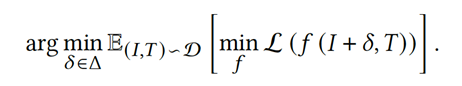
Untargeted Adversarial Perturbation.(UAP)方法:
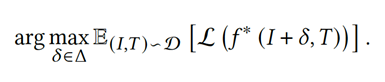
尽管EM和UAP可以应用于图像-字幕对,但它们未能实现高效的保护,尤其是UAP。我们探讨了这些方法从图像分类到多模态对比学习有效性下降的原因。
在图像分类中,EM和UAP优化具有相同标签的图像,使其在特征空间中收敛,导致模型容易捕获这些附加噪声并学习与标签的相关性,如图2(a)所示。
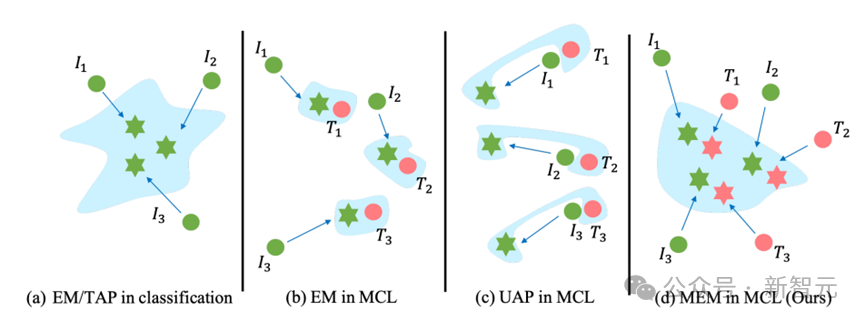
图2:不同方法在传统分类和多模态对比学习中的比较。𝐼表示图像,𝑇是配对的标题。蓝色区域是在不可学习样本上训练的模型的预期决策边界
但在多模态对比学习中,为了有效地应用EM和UAP方法,优化的图像噪声的方向必须与文本的特征相关,导致图像特征变得要么接近要么远离这些特征。
然而,不同对的文本特征可能在图像–文本数据集中广泛分散。如图2(b)和(c)所示,与分类不同,模型更难捕捉字幕和EM和UAP生成的噪声之间的相关性。
在图2(c)中,UAP的学习决策空间更加复杂,因此其保护效果不佳。
方法
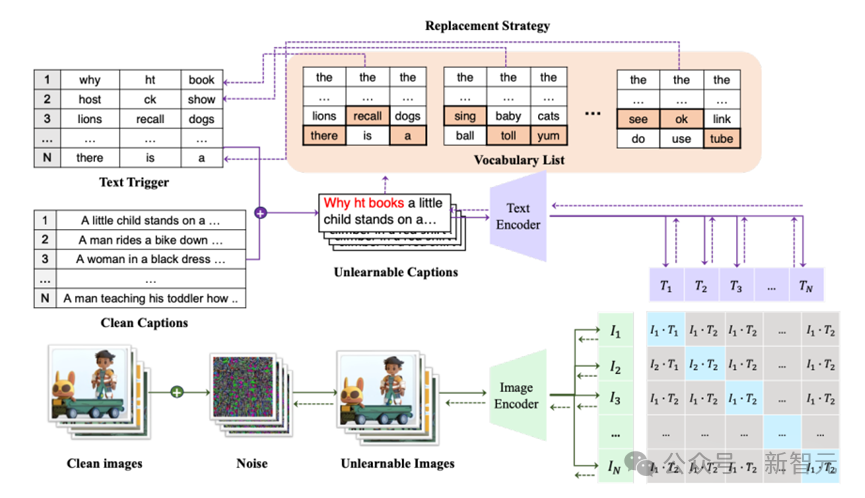
图3:多步误差最小化方法(MEM)的框架
由于图像-文本对的分散,基于代理模型的方法仍然无法实现有效的保护。一个直观的增强策略是同时优化图像和文本,以获得更大的优化空间,促进它们在特征空间中不同对的收敛。
因此,图像和文本集的优化特征表示呈现出相似的分布,便于模型学习它们的捷径,如图2(d)所示。
为此,我们以EM方法为基本框架,并提出在字幕前添加额外的短文本触发器来最小化对比损失,遵循对文本任务的对抗攻击的设置。我们的方法可以被概念化为一个三层迭代优化问题,类似于EM的多步过程。
具体来说,我们依次优化噪声δ和文本触发器t,以减少优化图像I + δ和优化文本T ⊕ t之间的对比损失,其中⊕表示可以在不同位置插入干净文本T的触发器。
为了简单起见,我们在本文中选择在文本的开头添加文本触发器。因此,我们的多步误差最小化(MEM)方法可以表述为:
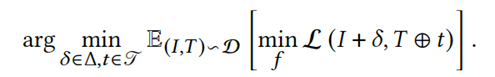
通过参考EM中的方法依次迭代优化上述问题。使用投影梯度下降(PGD)来解决式中的噪声最小化问题。
值得注意的是,为了减轻噪声对干净字幕的过拟合,我们通过在批处理中打乱干净字幕并添加正确匹配的文本触发器来增强它们。因此,当面对语义错误的字幕时,这种生成的噪声可以更多地关注文本触发器而不是部分字幕。因此,我们可以根据以下迭代公式获得最优的δ:
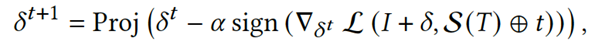
对于文本触发器最小化问题,首先通过在所有输入的前面重复单词「the」或「a」来初始化触发序列。
此外,基于HotFlip优化文本触发器,通过梯度近似替换标记的效果。通过更新每个触发标记的嵌入,以最小化当前标记嵌入周围的CLIP损失的一阶泰勒近似:
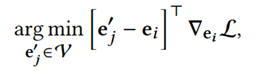
最后,我们可以在候选标记的集合中使用束搜索来搜索每个最优文本触发器。我们考虑来自上式的前k个候选者,并在触发器的每个位置从前到后搜索,并使用当前批处理上的损失对每个束进行评分。
我们遵循Wallace等人的方法,并使用小的束大小进行高效计算。在图3中,我们可以看到使用我们的MEM生成多模态不可学习样本的框架。
实验效果
有效保护性
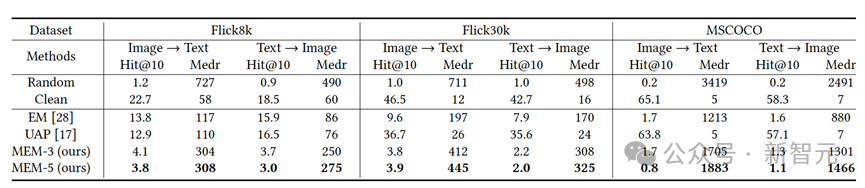
表1:在不同数据集上几种方法生成的不可学习样本的有效性比较
表1展示了它们在不同数据集上的检索结果。显然,UAP几乎无法为多模态数据提供任何保护,而EM则表现出一定程度的保护。
然而,我们的MEM始终为多模态数据提供强大的保护,将检索性能降低到几乎是随机猜测的一半。特别是MEM-5,由于其文本触发器更长,与MEM-3相比,在降低黑客模型性能方面取得了更大的效果。
图4展示了由不同方法生成的不可学习样本训练的训练损失下降曲线和在干净测试集上的检索Medr。从(a)中可以观察到,尽管EM使损失比正常训练下降得更快,但我们的方法MEM-3和MEM-5在第一个epoch时损失更小,这表明模型可以快速学习到捷径。
从(b)中我们发现,所有模型的Medr都比随机猜测时降低,但在不可学习样本上训练的模型停止学习得最快,达到了最差的检索结果,并且随着epoch的增加不会进一步学习得更好。以上观察结果与表1中的结果一致。
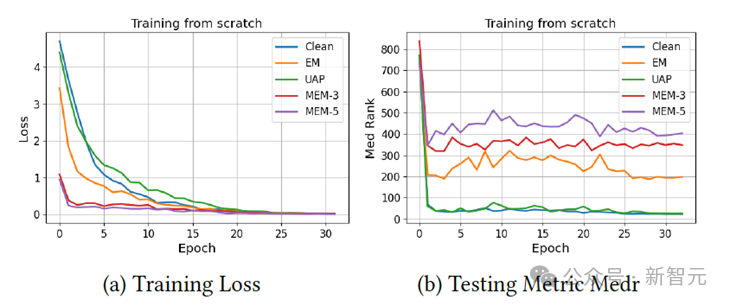
图4:训练损失和测试指标Medr的曲线变化记录
跨模型迁移性

表2:在不同模型架构上,基于ResNet50模型的MEM-3方法生成的不可学习样本的可转移性
我们假设数据保护是一个完全黑盒的设置,其中保护者不知道黑客模型的架构。因此,我们评估了在ResNet50代理模型上生成的MEM在不同黑客模型上的性能,包括ResNet101和ViT。结果如表2所示。我们发现这些样本可以成功地在不同模型之间转移,并能降低CLIP模型的性能。
可视化分析

图5:注意力图可视化:比较四种模型在干净数据和不同方法的不可学习样本上的情况
图5展示了在干净数据和不同方法生成的不可学习样本上训练的模型的注意力热图。对于图像,我们使用Grad-CAM来可视化模型的注意力,而对于文本,我们使用Integrated Gradients来可视化注意力。颜色越浅表示模型的注意力越高。
值得注意的是,对于图5(1),(2)和(3)中的模型都关注中心区域,这与字幕相关。
然而,图5(4)中由MEM – 3生成的样本训练的模型由于只学习了噪声特征,无法准确识别干净图像。同样在文本中,前三者中的模型都关注关键词「glass」,而后者中的模型将注意力放在前三个单词上,这可能是因为MEM-3总是优化噪声和前三个文本触发器来创建捷径。
这些可视化结果表明,EM和UAP在保护多模态数据方面效果不佳,而MEM具有明显的有效性。
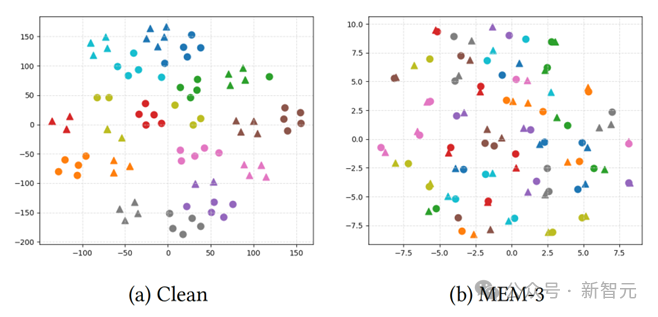
图6:干净样本和MEM-3优化的不可学习样本在干净模型和中毒模型下的t-SNE可视化
我们在图6中可视化了正常模型下干净样本的特征分布以及MEM3在中毒模型上优化的不可学习样本的特征分布。我们用三角形表示图像特征,用圆圈表示文本特征,相同颜色表示数据集中五个相同但经过变换的图像及其对应的不同描述。
从(a)中我们可以观察到,在干净模型下,相同的图像和文本在内部聚集在一起,并且相应的图像-文本对彼此接近。
然而,在(b)中,相同的图像和文本出现了分歧,只有成对的图像和文本彼此接近。这表明我们的方法有效地促进了模型学习噪声和文本触发器之间的捷径。
案例探讨:人脸隐私保护
我们进行了一个案例研究,将我们的MEM噪声应用于一个现实世界的场景:保护社交媒体平台上的个人人脸图像和相关信息,如姓名。
我们使用PubFig数据库进行了实验,这是一个大型的现实世界人脸数据集,包含从互联网上收集的200个个体的58,797张图像。对于检索评估,我们随机选择每个名人的一张照片作为测试集,并使用所有剩余的图像进行训练。
为了进行真实的微调,我们更改了他们的名字,并提供了一组与该名字相关的文本模板用于字幕生成。随后,我们使用MEM生成不可学习的样本,并使用不同的黑客模型进行评估。结果如表3所示。
MEM可以防止这些微调模型学习人脸和姓名特征之间的相关性,从而阻碍在测试集上的准确人员检索。

表3:在不同预训练模型上,ResNet50微调生成的不可学习样本的保护效果
结语
在本文中,我们探索了多模态数据保护,特别关注图像-文本对,我们生成了多模态不可学习样本来防止被多模态对比学习利用。我们将先前的分类方法扩展到这个背景下,揭示了由于模态增加和数据分散而存在的局限性。
鉴于这些发现,我们引入了一种名为多步误差最小化(MEM)的新颖生成方法,它基于EM框架。MEM有效地在噪声和文本触发器之间建立了捷径,并展示了在不同黑客模型之间的可转移性。
此外,我们使用各种可视化工具验证了我们方法的有效性。我们的工作开辟了一个新的方向,预计将适用于其他模态对,如音频-文本和音频-图像对。
作者介绍
本文作者来自中科院信工所、南洋理工大学、新加坡国立大学和中山大学。作者列表:刘心玮,加小俊,寻源,梁思源,操晓春。
其中,第一作者刘心玮是中科院信工所博士生。通讯作者中山大学操晓春教授和和南洋理工大学的加小俊博士后研究。
参考资料:
https://scst.sysu.edu.cn/members/caoxiaochun.html
https://jiaxiaojunqaq.github.io
