



作者丨陈鹭伊
编辑丨岑峰
语言模型的“小时代”正式到来?
北京时间8月1日凌晨(当地时间7月31日下午),Google深夜放出大招,发布了其Gemma系列开源语言模型的更新,在AI领域引发了巨大的震动。Google Developer的官方博客宣布,与6月发布的27B和9B参数版本相比,新的2B参数模型在保持卓越性能的同时,实现了“更小、更安全、更透明”的三大突破。
Gemma 2 2B版本,这一通过蒸馏学习技术精心打磨的成果,不仅优化了NVIDIA TensorRT-LLM库,更在边缘设备到云端的多种硬件上展现出了卓越的运行能力。
更重要的是,较小的参数量大大降低了研究和开发的门槛,使得Gemma 2 2B能够在Google Colab的免费T4 GPU服务上流畅运行,为用户带来了灵活且成本效益高的解决方案。
大模型竞技场LMsys上,Gemma 2 2B的发布也迅速引起了广泛关注。LMsys第一时间转发了Google Deepmind的推文,对超越了参数量10倍于Gemma 2 2B版本的“老前辈”GPT-3.5-Tubro表示祝贺。
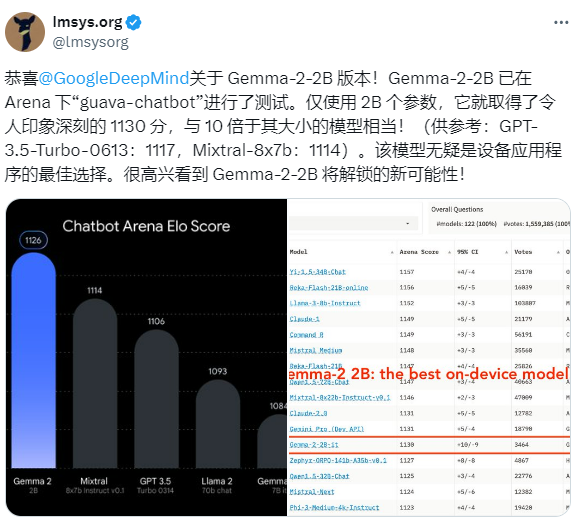
Google在与OpenAI的LLM竞争中虽然未能胜出,但其SLM的发展势头却愈发强劲。今年二月,Google 推出了 Gemma 系列模型,这些模型设计更为高效和用户友好。Gemma 模型可以轻松运行在各种日常设备上,如智能手机、平板电脑和笔记本电脑,无需特殊硬件或复杂优化。
Gemma 2模型的技术创新点在于引入了Gemma Scope功能,这是一套开放的稀疏自编码器(Sparse AutoeEncoders, SAEs),新模型包含400多个SAEs,用于分析 Gemma 2 2B 和 9B 模型的每一层和子层,为研究人员提供了理解语言模型内部工作原理的强大工具。
Google Deepmind 语言模型可解释性团队则是通过官方博客对 Gemma Scope 进行了更多的技术分析。该团队称,Gemma Scope旨在帮助研究人员理解Gemma 2语言模型的内部工作原理,推动可解释性研究,构建更强大的系统,开发模型幻觉保护措施,防范自主AI代理的风险。稀疏自动编码器(SAE)将作为“显微镜”,帮助研究人员观察语言模型内部。
值得注意的是,尽管Gemma 2 2B为开发者提供了一种灵活且成本效益高的解决方案,但在训练阶段仍然需要投入大量的计算资源。根据Deepmind博客,Gemma Scope的训练使用了约相当于15%的Gemma 2 9B训练计算资源(或GPT3的22%训练计算资源)。
在Gemma 2 2B发布后,业界反响热烈。雷峰网GAIR硅谷自动驾驶峰会(2018)嘉宾、UC Berkeley教授Anca Dragan (推特:@ancadianadragan )第一时间发表多条推文对Gemma 2的SAE机制进行了解读。她表示,如此大的计算资源使得纯粹的学术研究机构难以参与其中,但之后学术界会进一步关注如何利用Gemma Scope的SAE机制来提高模型的解释性和AI的安全性。
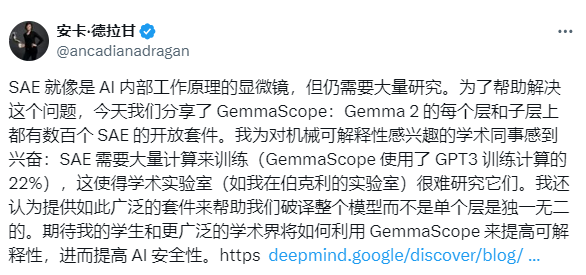
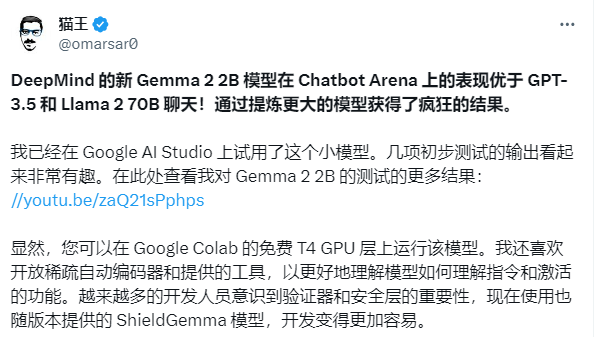
计算语言学家、DAIR.AI的联合创始人Elvis Saravia (推特:@omarsar0 )也在第一时间对Gemma 2 2B进行了测试,对Gemma 2的SAE机制给予了高度评价。
随着2024年的到来,大模型的光环似乎正在逐渐褪去,而如何将模型做小,正成为今年语言模型发展的重要趋势。2023年的“百模大战”虽然激烈,但大模型的商业价值有限;相比之下,小模型在成本和效率上展现出了更大的优势。
甚至“暴力美学”的倡导者、OpenAI CEO Sam Altman也早早承认,“大模型”时代可能走向结束,未来我们会通过其他方式来改进它们。

在技术上,通过如蒸馏压缩和参数共享等手段,可以显著降低模型规模同时保持性能。Gemma 2 2B版本的亮眼表现,无疑为下一步的大模型研究提供了重要方向。
Google的另一系列语言模型Gemini,以其不公开源代码的特性,专为Google自家产品及开发者使用,与Gemma系列形成鲜明对比。而META的Llama系列则高举“开源”大旗,向OpenAI的GPT系列发起了强有力的挑战。
在过去一年中,OpenAI的GPT系列一直是这个领域无可争议的“王者”,在LMsys的“大模型竞技场”,GPT-4及其后续版本GPT4-o在大多数时间一直牢牢占据第一的位置,仅有一次被Claude 3.5 Sonnet短暂超越。
但在2024,开始有越来越多的模型向GPT系列发起了冲击。除了Google的Gemini和Gemma系列外,另一有力竞争者是META的Llama系列。与OpenAI的闭源(OpenAI也因此称为”Close AI”)路径不同,META的Llama系列则是高举开源大旗的代表。
就在数天前,Meta CEO马克·扎克伯格(Mark Zuckerberg)在“史上最强开源模型”Llama 3.1发布之际,发表了题为“Open Source AI is the Path Forward”的公开信,强调了开源AI在推动AI发展中的重要性。

在Llama 3.1发布后,META AI首席人工智能学家、2018年图灵奖得主Yann Lecun(推特:@ylecun)除了发布了多篇技术角度的推文外,昨天还转发了科技网站Arstechnica的一篇关于“人工智能安全”法案SB1047看法的文章,为“开源AI”争取空间。

值得注意的是,虽然Llama系列在以大众评分为依据的LMsys“大模型竞技场”上不敌GPT-4系列,但在另一个以专家评分的竞技场“Scale Leadboard”上却在多个项目中超越了GPT-4系列。目前在Scale Leadboard的6个评测项目上,GPT-4系列仅在Spanish(西班牙语)和Methodology(方法论)上领先。
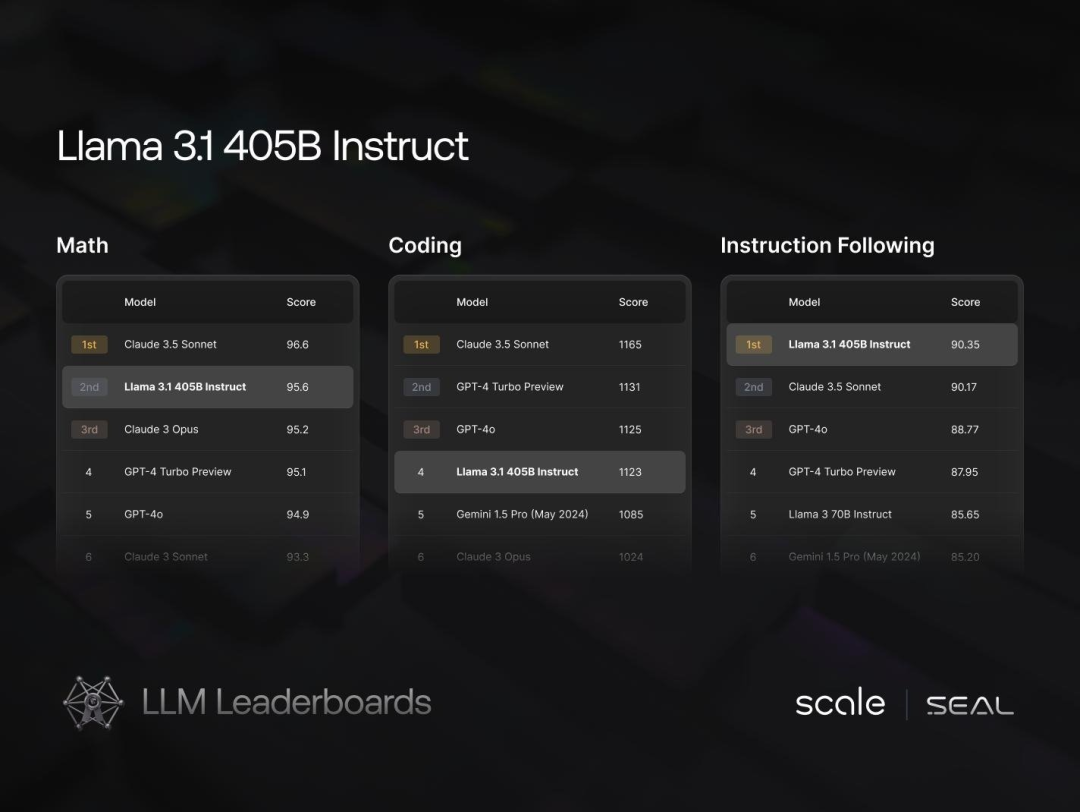
“Scale Leadboard”是由AI数据标注创企业Scale.ai所创立的排行榜。其创始人、95后华裔天才Alexanda Wang是当前硅谷最受关注的创业新星之一,目前Scale.ai为几乎所有领先的AI模型提供数据支持,并与OpenAI、Meta、微软等组织保持良好关系。目前Scale.ai的估值为138亿美元。
Gemma 2的发布,不仅是Google在AI领域的一次自我超越,更是对整个行业的一次挑战。无论是“小型化”还是“开源”,都预示着2024年将是语言模型研究的又一个春天。让我们拭目以待,Gemma 2代表的“小模型”将如何重塑AI的未来。
让大模型的暴风雨来得更猛烈些吧。
