
智东西8月2日报道,昨日晚间,开源文生图模型霸主Stable Diffusion原班人马,宣布推出全新的图像生成模型FLUX.1。
FLUX.1包含专业版、开发者版、快速版三种模型,其中前两款模型击败SD3-Ultra等主流模型,较小规模的FLUX.1[schnell]也超越了Midjourney v6.0、DALL·E 3等更大的模型。
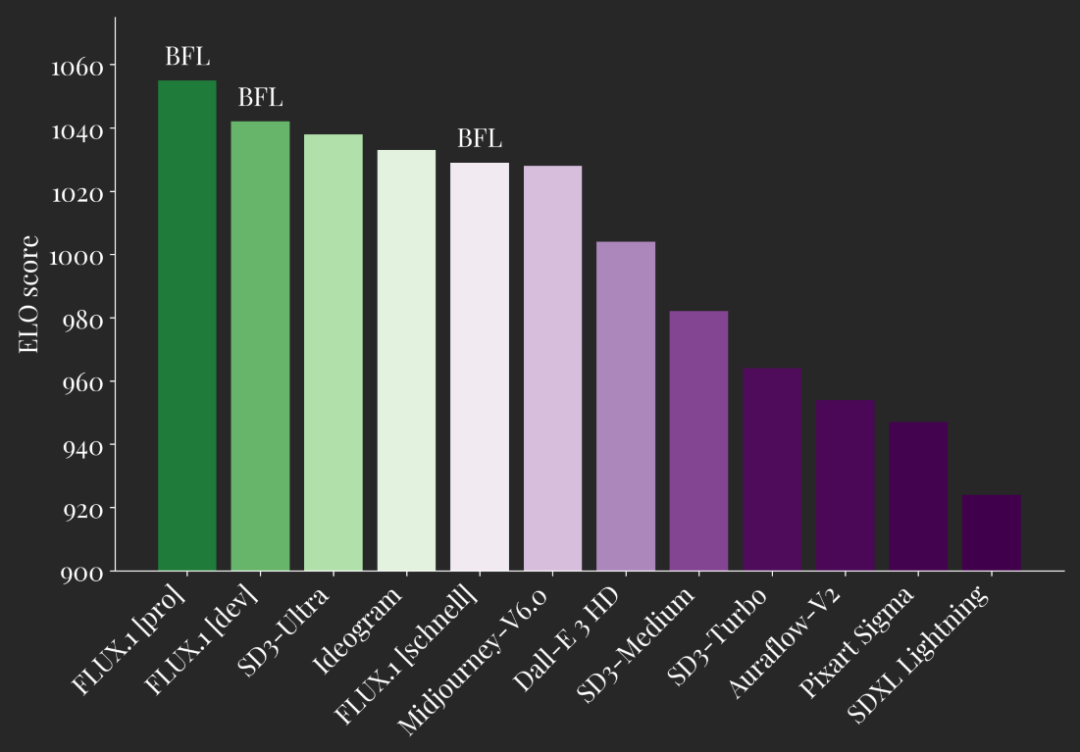
▲FLUX.1 ELO分数与主流模型对比
FLUX.1在文字生成、复杂指令遵循和人手生成上具备优势。以下是其最强的专业版模型FLUX.1[pro]生成图像示例,可以看到即使是生成大段的文字、多个人物,也没有出现字符、人手等细节上的错误。
▲FLUX.1[pro]生成图像示例
FLUX.1现已在开源平台Replicate上可用,以下是我用提示词“世界上最小的黑森林蛋糕,手指大小,被黑森林的树木包围”,在三款模型上生成的图像,用时分别为17.5s、12.2s、1.5s。

▲三款模型生成对比
FLUX.1同时开放了API(应用程序接口),按图像张数定价,三款模型的价格依次为每张图片0.055美元、0.03美元、0.003美元(约合人民币0.4元、0.22元、0.022元)。
FLUX.1背后的公司名为Black Forest Labs(黑森林实验室),由Stable Diffusion原班人马、多位Stability AI前研究员成立。与Stability AI类似,黑森林致力于研发优质多模态模型并开源,目前已完成3100万美元(约合人民币2.25亿元)的种子轮融资。
黑森林还预告不久之后将发布SOTA(当前技术指标第一)视频模型。从其放出的Demo来看,无论是流畅度、稳定性还是物理模拟都达到第一梯队水平,该公司或许会成为视频生成领域的一匹黑马。
▲视频生成模型预告
https://replicate.com/black-forest-labs/flux-pro
https://replicate.com/black-forest-labs/flux-dev
https://replicate.com/black-forest-labs/flux-schnell
FLUX.1在视觉质量、图像细节和输出多样性等方面性能优越,其具有三大特点:文字生成、复杂构图、人手描绘。
文字的生成在图像、视频生成中非常重要,许多模型容易混淆看起来相似的字母。FLUX.1可以处理重复字母的棘手单词,例如生成一个黑森林Flux Schnell蛋糕:

▲黑森林Flux Schnell蛋糕
在构图方面,FLUX.1擅长按照图像中事物应该位于哪里等复杂指示进行操作。例如,FLUX.1完美地演绎了这段提示词:三个魔法巫师站在一张黄色桌子上,每个巫师都拿着一个标志。左边,一个穿着黑色长袍的巫师拿着一个写着“AI”的标志;中间,一个穿着红色长袍的女巫拿着一个写着“is”的标志;在右边,一个穿着蓝色长袍的巫师拿着一个写着“cool”的标志。

▲复杂构图
人手一直是多模态生成模型的重灾区。FLUX.1生成的人手图像虽然还不够完美,但实现了很大的进步。

▲人手
FLUX.1共有专业版、开发者版、快速版三种版本。
其中,FLUX.1[pro]是最先进的一个版本,具有顶级的即时跟踪、视觉质量、图像细节和输出多样性,面向专业用户提供定制的企业解决方案。

▲FLUX.1[pro]生成图像示例
FLUX.1[dev]面向非商业应用,它从FLUX.1[pro]提炼而来,具有相似的质量和能力,同时比相同尺寸的标准模型更高效。
▲FLUX.1[dev]生成图像示例
FLUX.1[schnell]是三款模型中最快的,专为本地开发和个人使用而定制,并根据Apache 2.0标准许可公开提供。
▲FLUX.1[schnell]生成图像示例
FLUX.1现已在开源平台Replicate上可用,只需一行代码即可在云端运行,用户也可以下载模型权重并以编程方式运行。FLUX.1的API也同步开放,三款模型的价格依次为每张图片0.055美元、0.03美元、0.003美元(约合人民币0.4元、0.22元、0.022元)。
性能方面,FLUX.1经过特别微调,在预训练中保留了整个输出多样性,在指令遵守、视觉质量、尺寸/长宽变化等多个方面树立了新标准。
其中FLUX.1[pro]和[dev]两款模型,在5项测评标准中都超过了Midjourney v6.0、DALL·E 3和SD3-Ultra等热门模型。
FLUX.1[schnell]作为轻量级模型,不仅优于同类竞争对手,还优于Midjourney v6.0、DALL·E 3等强大的非蒸馏模型。
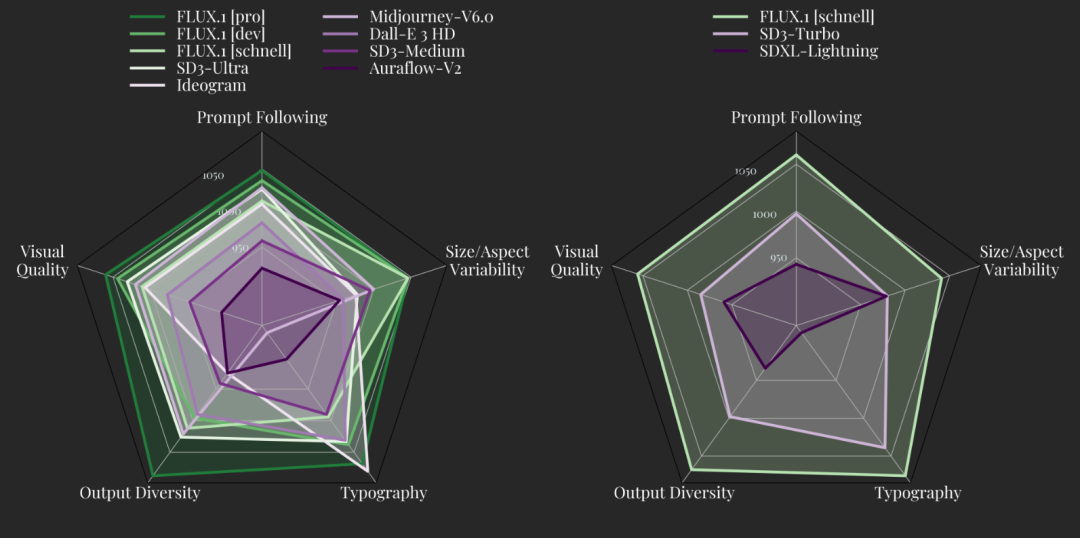
▲FLUX.1性能与主流模型对比
此外,所有FLUX.1模型均支持0.1和2.0百万像素的多种宽高比和分辨率。
▲宽高比/分辨率变化
在模型架构上,FLUX.1采用基于多模态和并行扩散Transformer模块的混合架构,并将其扩展到12B参数。
团队通过建立流匹配(Flow Matching)来改进最先进的扩散模型,并通过结合旋转位置嵌入(Rotary Position Embedding)和并行注意力层,来提高模型性能和硬件效率。更详细的技术报告将在不久后发布。
黑森林实验室由Stable Diffusion的创始团队成立,该团队此前的工作还包括高质量图像生成模型VQGAN、视频生成模型Stable Video Diffusion等。
Stable Diffusion最初的5位作者中,4位曾加入Stability AI并持续开发SD后续版本的成员,包括Robin Rombach、Andreas Blattmann、Dominik Lorenz以及Patrick Esser,都在黑森林实验室的创始团队中。
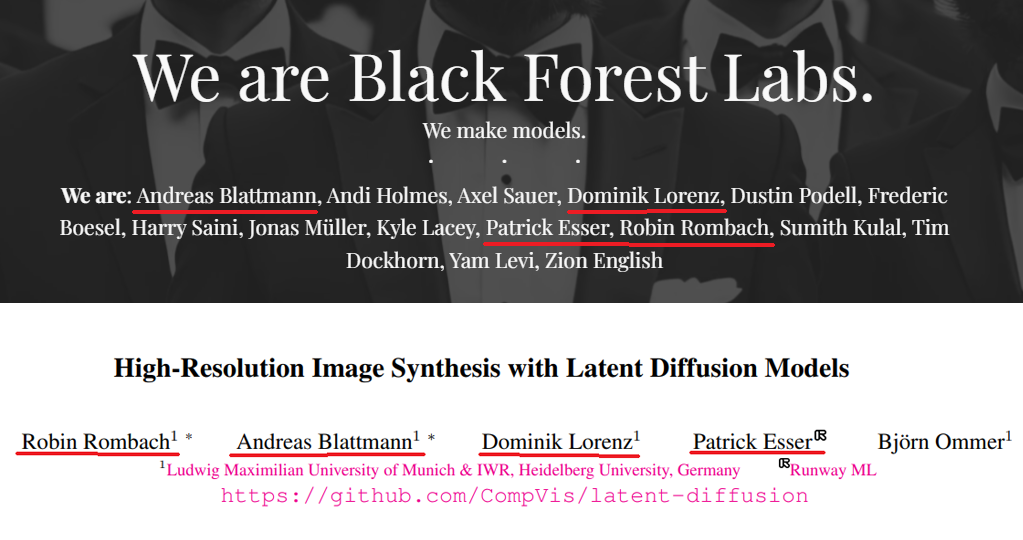
▲Stable Diffusion作者、黑森林实验室创始团队
该团队称,其核心信念是开发广泛可访问的模型,促进研究界和学术界的创新和协作,并提高模型透明度。
黑森林实验室宣布已完成3100万美元(约合人民币2.25亿元)的种子轮融资,由知名风投机构a16z(Andreessen Horowitz)领投,VR制造商Oculus的CEO Brendan Iribe、创企孵化器YC的CEO陈嘉兴(Garry Tan)、英伟达研究员Timo Aila等专家及AI公司跟投,还收到了来自General Catalyst等一线基金的后续投资。
该团队的顾问委员会,包括在内容创作行业拥有丰富经验的前迪士尼总裁Michael Ovitz,以及神经风格转换的先驱Matthias Bethge教授。
刚刚创业的AI大神安德烈·卡帕西(Andrej Karpathy)为黑森林团队送上祝福,并称“开源的FLUX.1图像生成模型看起来非常强大”。
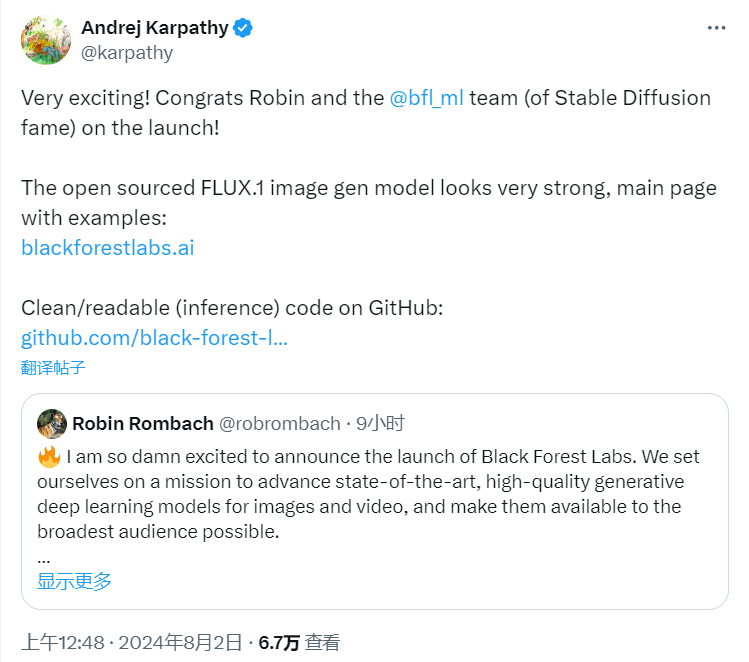
▲卡帕西评论
创始团队的前领导——Stability AI前CEO埃马德·莫斯塔克(Emad Mostaque)也发来贺电,还说“之前能与他们合作是我的荣幸,我相信他们会继续在生成每一个像素的旅程中突破界限”。

▲莫斯塔克评论
在下一步的工作上,黑森林预告将发布一款SOTA文生视频模型,“让所有人都能将文本转为视频”。该模型将建立在FLUX.1的基础上,“以高清和前所未有的速度实现精确创作和编辑”。
▲视频生成模型预告
在众多大厂、创企狂卷文生视频之际,文生图领域突然迎来黑马。“横空出世”的FLUX.1的不仅展现出卓越的性能,在文字生成、复杂构图、人手描绘等方面突破难关,还以多样化的版本满足不同用户的需求。
黑森林实验室凭借着Stable Diffusion原班人马的强大实力,获得了丰厚的种子轮融资,也吸引了众多行业大咖的关注与支持。其后续将发布的视频模型,又将为文生视频领域注入新的活力。



