大模型作为当下 AI 工业界和学术界当之无愧的「流量之王」,吸引了大批学者和企业投入资源去研究与训练。随着规模越做越大,系统和工程问题已经成了大模型训练中绕不开的难题。例如在 Llama3.1 54 天的训练里,系统会崩溃 466 次,平均 2.78 小时一次!

那么,频繁存储检查点就显得十分必要。但存储检查点本身也是一个大工程。

Meta 做了很多努力来加速存储检查点时间和增加存储频率,来对抗频繁出现的系统失效。但频繁存储也意味着大量的存储资源开销,其训练集群配备了 240PB 的 SSD 来应对这一挑战,光存储这一项的耗费就要亿元!
华为诺亚的 ExCP 方法也就应运而生,为了应对存储带来的巨大开销,他们提出了极致压缩检查点技术,能够无损压缩模型 70 倍,大幅降低训练中的存储开销。
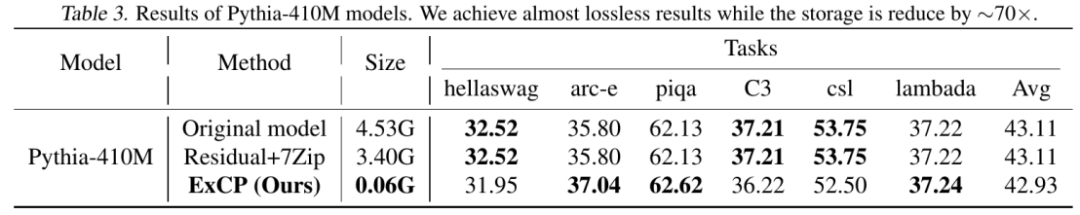
代码目前已经开源,在 Apache 2.0 框架下发布,issue 中已经有小伙伴成功复现了结果。

-
文章地址:https://arxiv.org/abs/2406.11257
-
仓库地址:https://github.com/Gaffey/ExCP
方法也很有创新性,文章中提到了两个重要的概念,一个是利用训练中检查点的残差信息,通过时间序列上信息的稀疏性实现更高的剪枝比例;另一个是将优化器和权重联合起来进行压缩,实现整体的高压缩率。
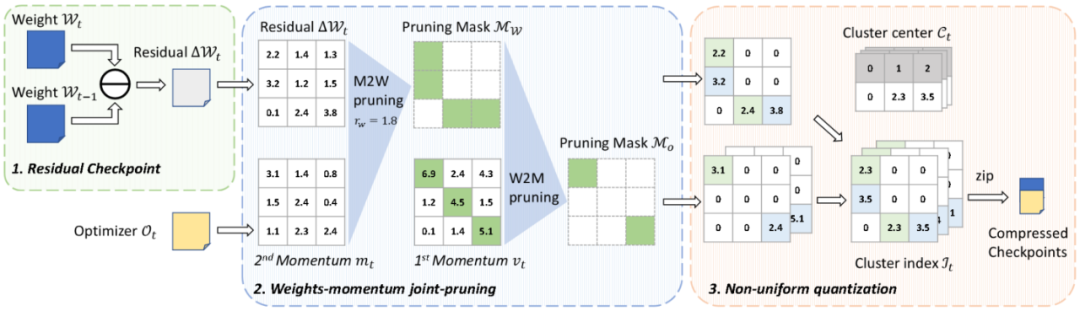
在训练过程中,当前的参数可以看作上一个检查点存储的权重加上逐次迭代时梯度更新的总和,这部分是相对稀疏的,包含的信息量较少,因此对这一残差进行压缩,可以获得更好的压缩比例。而与此相反的,优化器中存储的动量是梯度一阶矩和二阶矩的滑动平均值,对于一阶矩来说,它的滑动平均默认的参数是 0.9,在数百到数千个迭代之后与上一次检查点存储的内容已经没有太大的关联,所以对于优化器直接压缩其本身的值而非残差。最终待压缩的检查点表示为
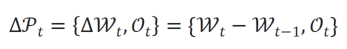
目前已有的模型压缩相关的工作一般只关注于模型的推理性能,或者是模型最终存储检查点的大小,而不关注模型在整个训练过程中对储存空间的开销。因而已有工作只对权重进行压缩,而忽略了 Adam 等常见优化器中实际上存储了两倍于权重数量的动量。这一工作一方面将两者一起进行了压缩,显著提升了整体的压缩比例;另一方面也利用了权重和优化器动量的关联性,进一步提升彼此的压缩比例。
权重剪枝:由于剪枝的权重是残差值,优化器动量的二阶矩可以大致表示在过去一段时间内权重残差值的变化幅度,所以可以使用优化器动量的二阶矩作为指标来确定不同层的剪枝比例。剪枝策略如下文公式所示
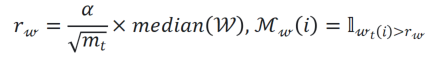
式中,W 和 分别表示权重和二阶矩。
优化器动量剪枝:对于动量剪枝,可以使用一阶矩作为指示器来进行剪枝,论文中有关于可收敛性的一个简要证明。同时,如果一个位置的权重已经被剪枝,那么对应位置的优化器动量也应该同步被处理,所以剪枝策略如下文公式所示
分别表示权重和二阶矩。
优化器动量剪枝:对于动量剪枝,可以使用一阶矩作为指示器来进行剪枝,论文中有关于可收敛性的一个简要证明。同时,如果一个位置的权重已经被剪枝,那么对应位置的优化器动量也应该同步被处理,所以剪枝策略如下文公式所示
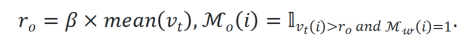
式中,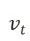 表示一阶矩。
整体压缩流程如 Algorithm 1 所示,依次进行计算权重残差 / 联合压缩 / 非均匀量化 / 编码压缩等步骤,得到最终的压缩结果。
表示一阶矩。
整体压缩流程如 Algorithm 1 所示,依次进行计算权重残差 / 联合压缩 / 非均匀量化 / 编码压缩等步骤,得到最终的压缩结果。

而恢复出检查点完整文件的流程则如 Algorithm 2 所示,进行解压缩之后,首先从非均匀量化后存储的码本和下标中恢复出浮点结果,然后再与基准权重(上一个检查点的原始权重或恢复出的重建权重)相加,得到检查点完整文件。而恢复出整个训练流程中的检查点文件的流程如 Algorithm 3 所示,在完成训练后只保存初始化权重的随机种子和每个检查点存储的压缩结果,然后依次对检查点进行恢复以得到完整的检查点序列,以供从其中选择某个或多个检查点恢复训练 / 进行测试等。
文章中不仅对于大语言模型做了评估,在 ViT-L32 这样较大的视觉模型上这一方法也能取得很好的效果。
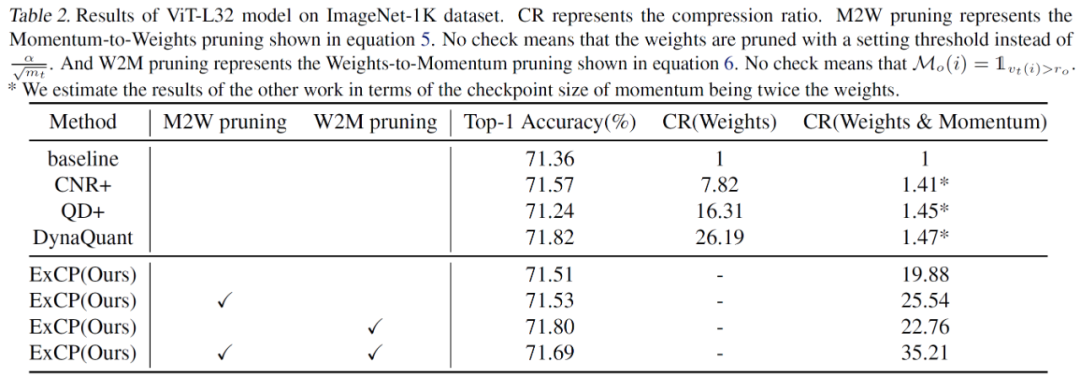
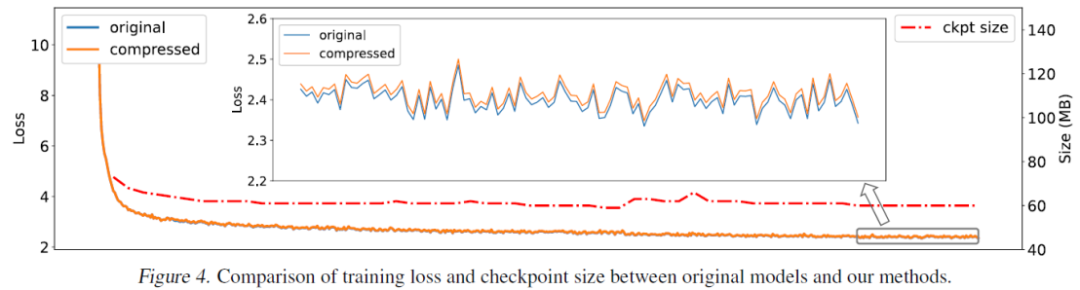
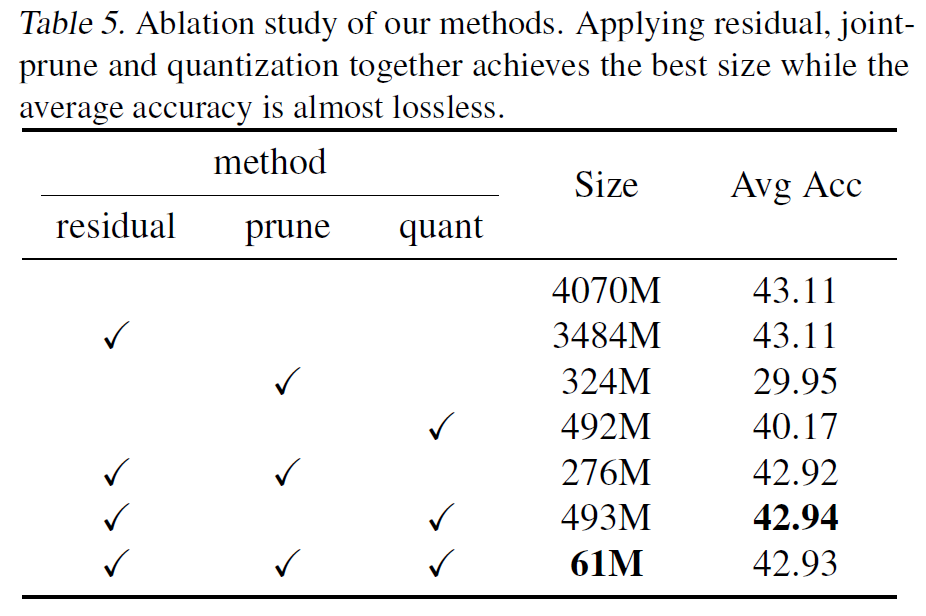
从消融实验里也可以看出,采用残差剪枝的方法大大减少了剪枝带来的损失。
文章中还提供了大语言模型压缩前后问答的样例,可以看到压缩本身对于模型的问答能力也没有造成损害。




