近两日,谷歌在不断发布最新研究。继昨日放出最强端侧 Gemma 2 2B 小模型后,刚刚,Gemini 1.5 Pro 实验版本 (0801) 已经推出。
用户可以通过 Google AI Studio 和 Gemini API 进行测试和反馈。
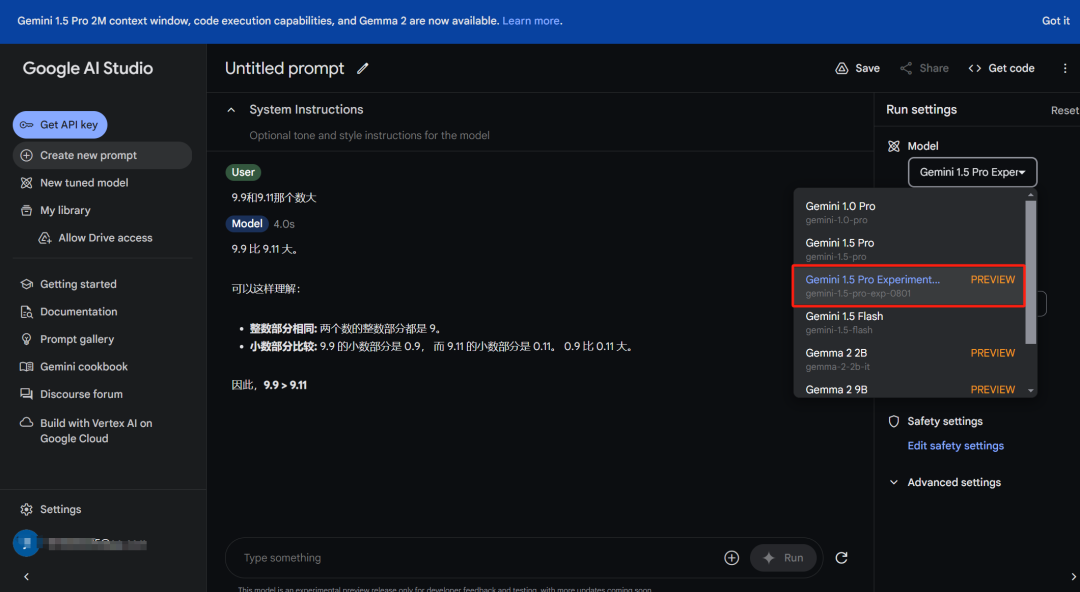
既然免费,那我们帮大家测试一下最近比较火的比大小问题。当我们问 Gemini 1.5 Pro (0801) 9.9 和 9.11 哪个数大时,模型一次就能回答正确,并给出了理由。
当我们继续追问「Strawberry 单词里面有多少个 r」时,然而 Gemini 1.5 Pro (0801) 却翻车了。在提示语中施加「咒语」一步一步来,模型分析到第四步就出错了。
-
Google AI Studio 测试地址:https://aistudio.google.com/app/prompts/new_chat
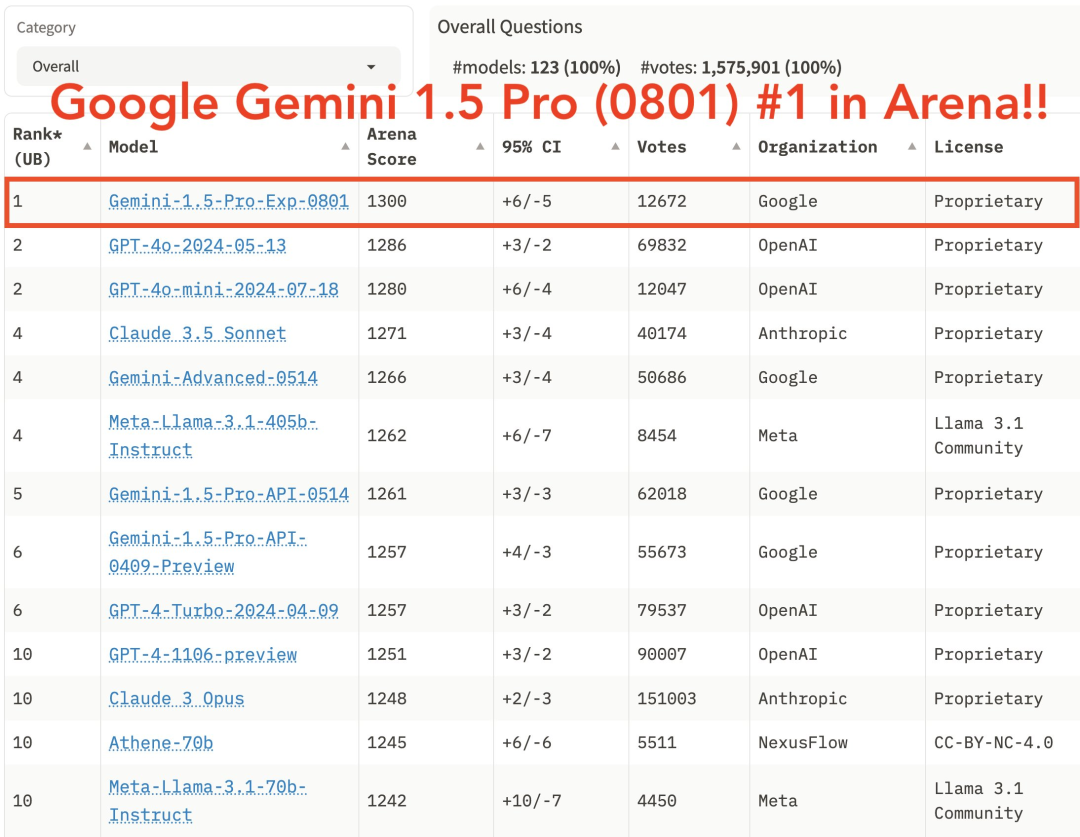
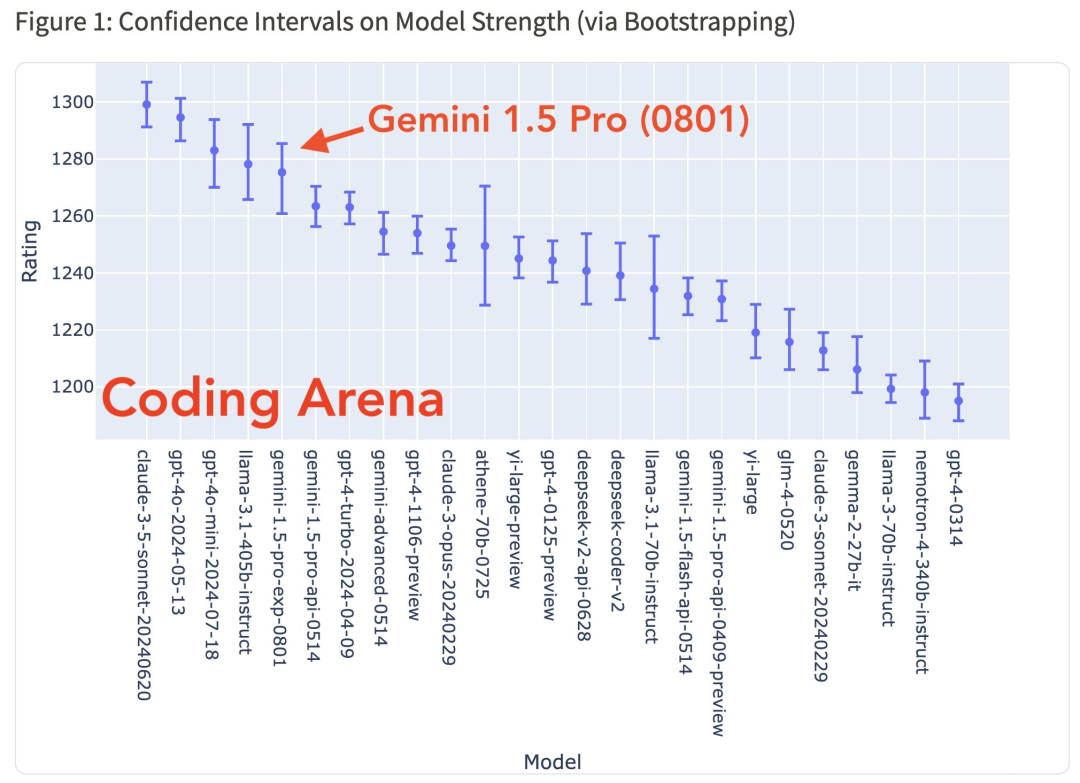
不过,从官方评测来看,Gemini 1.5 Pro (0801) 各项指标还是很能打的。新模型迅速夺得著名的 LMSYS Chatbot Arena 排行榜榜首,并拥有令人印象深刻的 ELO 分数,得分为 1300。
这一成就使 Gemini 1.5 Pro (0801) 领先于 OpenAI 的 GPT-4o(ELO:1286)和 Anthropic 的 Claude-3.5 Sonnet(ELO:1271)等强大竞争对手,这或许预示着人工智能格局的转变。
Gemini 团队关键成员 Simon Tokumine 称 Gemini 1.5 Pro (0801) 是谷歌迄今为止制造的最强大、最智能的 Gemini (模型)。
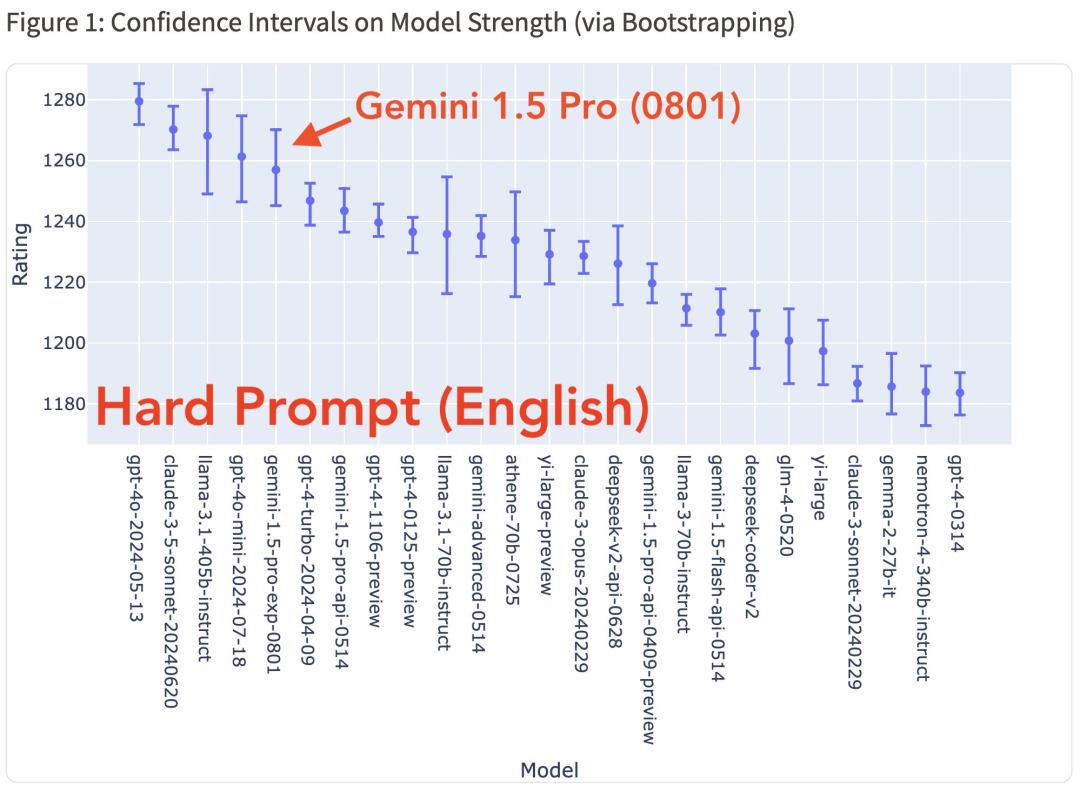
除了拿到 Chatbot Arena 榜首,Gemini 1.5 Pro (0801) 在多语言任务、数学、Hard Prompt 和编码等领域也表现相当出色。
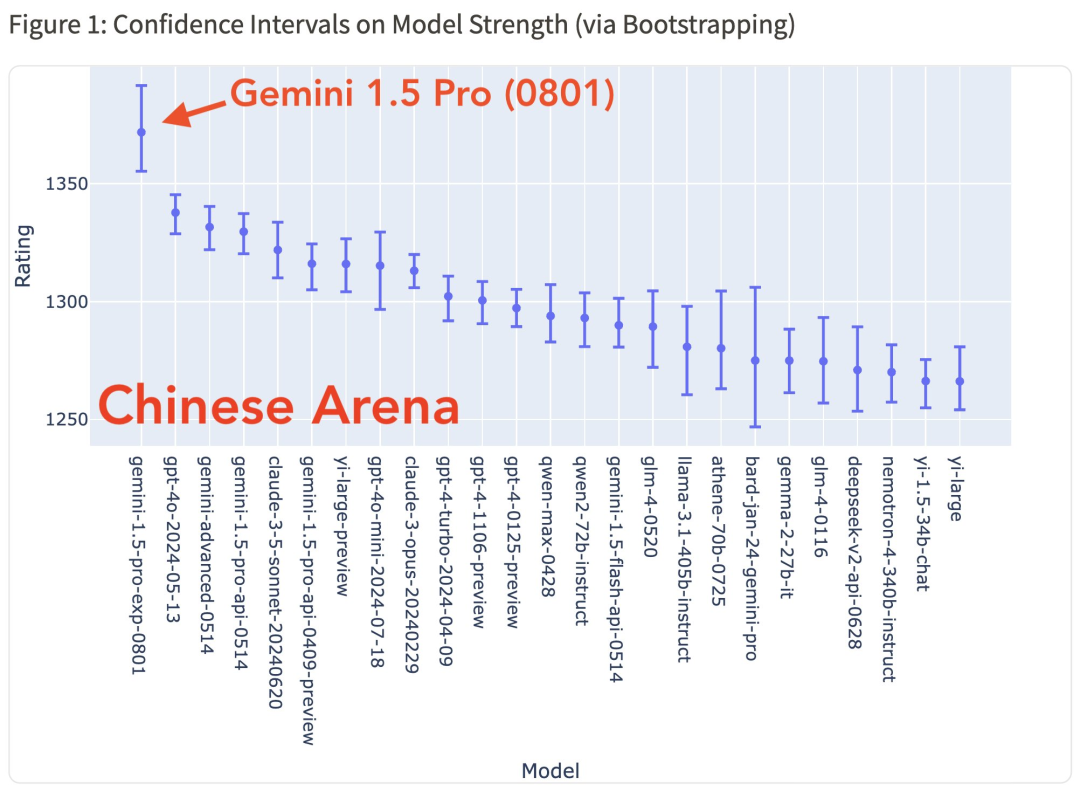
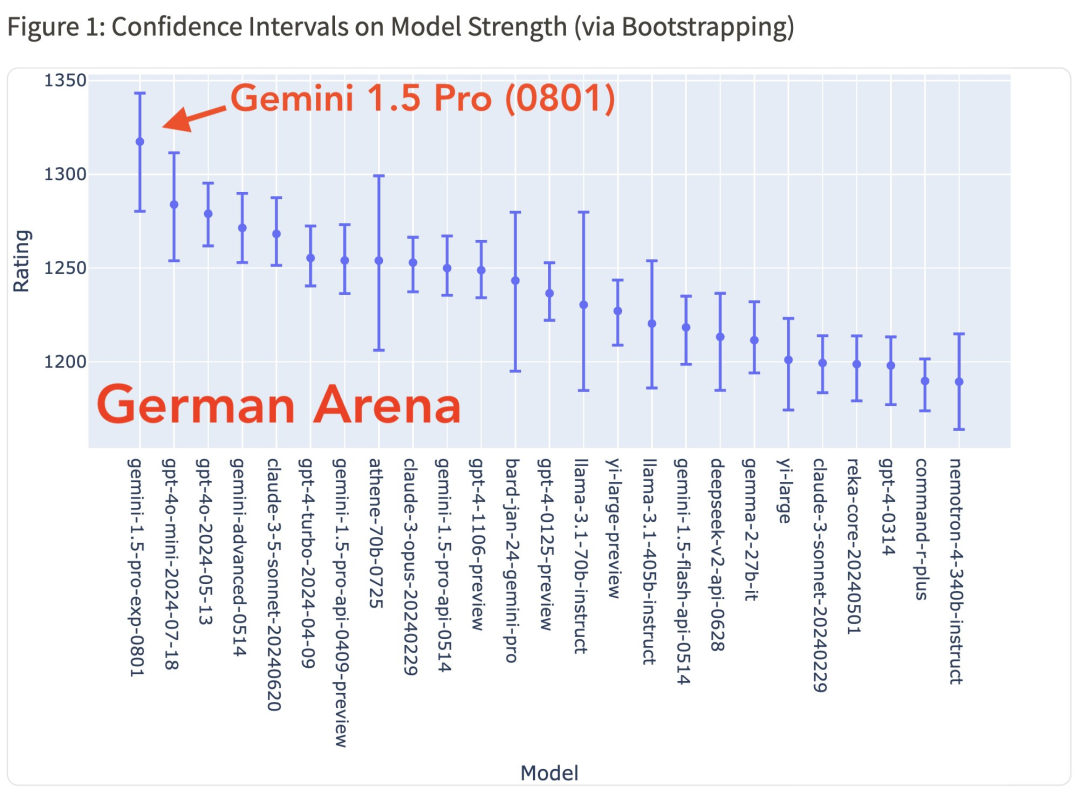
具体而言,Gemini 1.5 Pro (0801) 在中文、日语、德语、俄语方面均表现第一。
但在编码、Hard Prompt 领域,Claude 3.5 Sonnet、GPT-4o、Llama 405B 仍然处于领先地位。
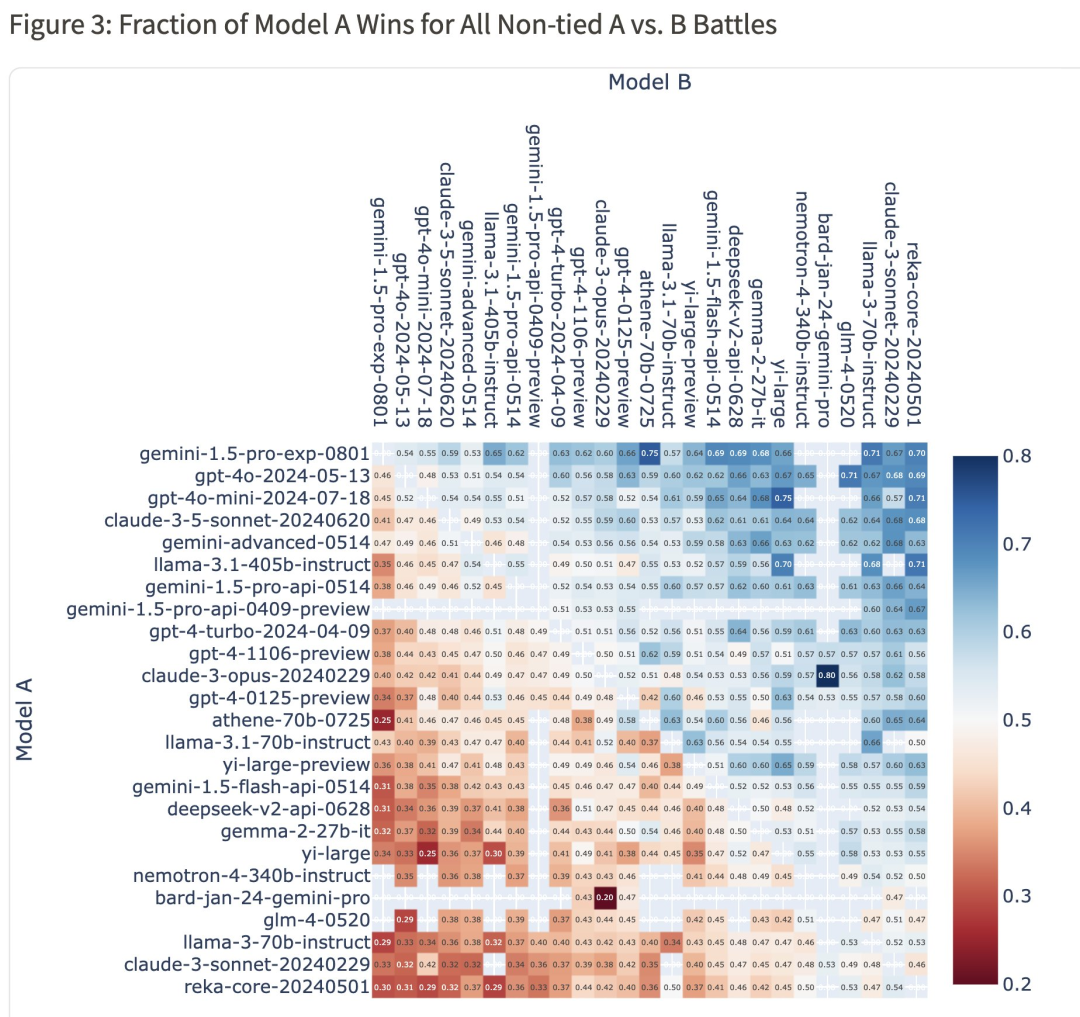
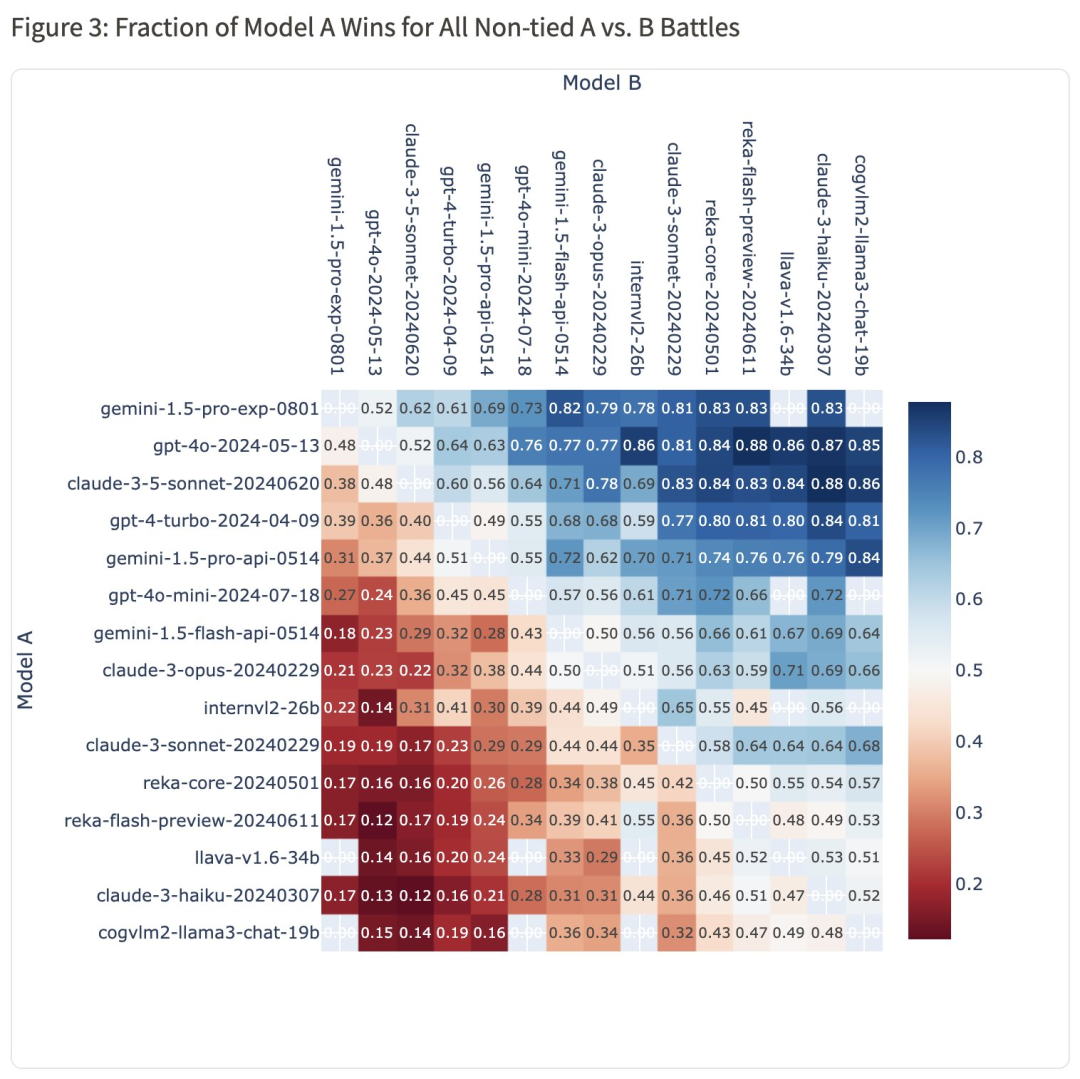
在 win-rate 热图上:Gemini 1.5 Pro (0801) 对阵 GPT-4o 的胜率为 54%,对阵 Claude-3.5-Sonnet 的胜率为 59%。
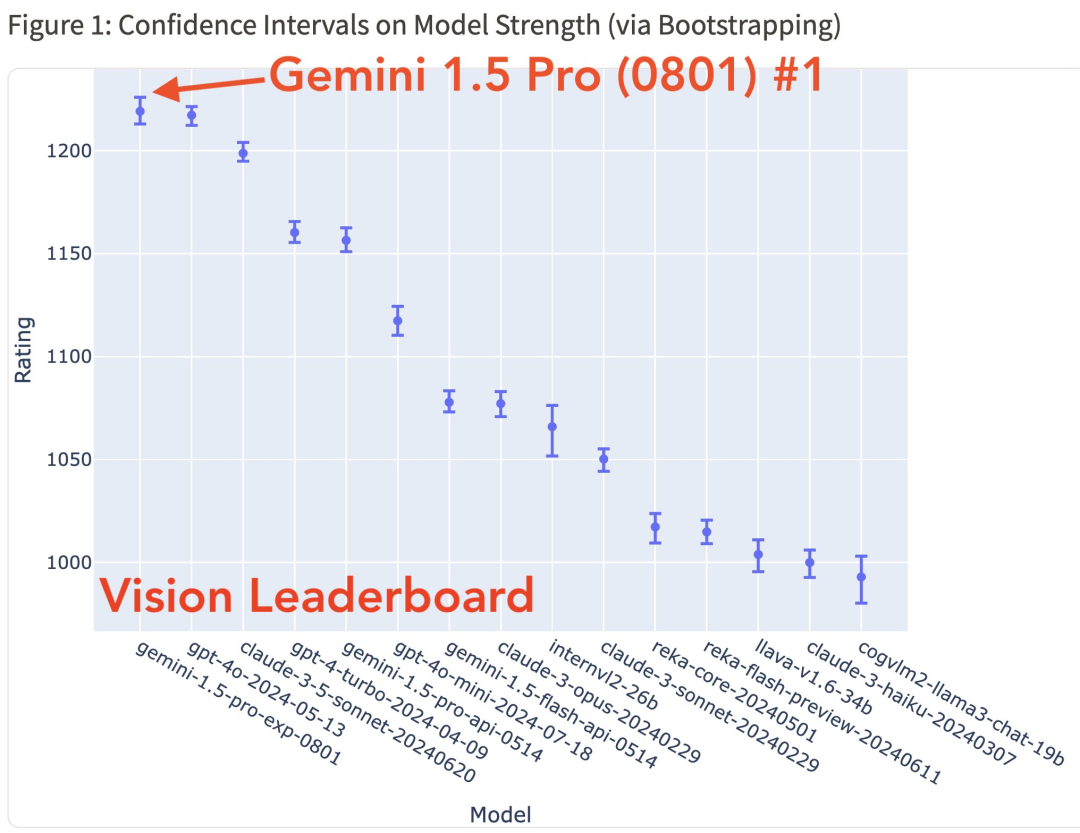
Gemini 1.5 Pro (0801) 在 Vision 排行榜上也第一!
网友纷纷表示,谷歌这次真是出乎所有人的预料,没有提前官宣就突然开放测试最强模型,这次压力给到了 OpenAI。
虽然 Gemini 1.5 Pro (0801) 取得了很高的成绩,但它仍处于实验阶段。这意味着该模型在广泛使用之前可能会进行进一步的修改。
有网友对 Gemini 1.5 Pro (0801) 的内容提取能力、代码生成能力、推理能力等进行了测试,我们来看下他的测试结果。
来源:https://x.com/omarsar0/status/1819162249593840110
首先,Gemini 1.5 Pro (0801) 的图像信息提取功能很强,例如输入一张发票图像,将发票细节用 JSON 格式编写出来:
再来看下 Gemini 1.5 Pro (0801) 的 PDF 文档内容提取功能,以经典论文《Attention Is All You Need》为例,提取论文章节目录:
让 Gemini 1.5 Pro (0801) 生成一个帮助学习大型语言模型(LLM)知识的 Python 游戏,该模型直接生成了一整段代码:
值得一提的是,Gemini 1.5 Pro (0801) 还给出了详细的代码解释,包括代码中函数的作用、该 Python 游戏的玩法等等。
这段程序可以直接在 Google AI Studio 中运行,并且可以试玩,例如做道关于 Tokenization 定义的选择题:
如果觉得选择题太简单无聊,可以进一步让 Gemini 1.5 Pro (0801) 生成一个更复杂的游戏:
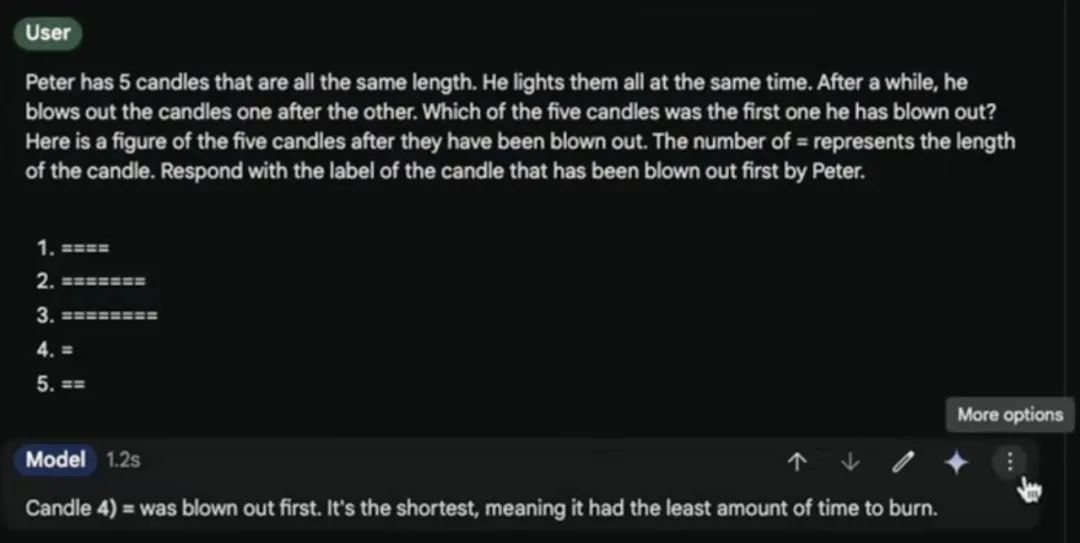
为了测试 Gemini 1.5 Pro (0801) 的推理能力,网友提问了一个「吹蜡烛」问题,但模型回答错误:
尽管有一些瑕疵,但 Gemini 1.5 Pro (0801) 的确表现出接近 GPT-4o 的视觉能力,以及接近 Claude 3.5 Sonnet 的代码生成和 PDF 理解、推理能力,值得期待。
参考链接:
https://www.youtube.com/watch?v=lUA9elNdpoY
https://x.com/lmsysorg/status/1819048821294547441