热门通用大模型 Agent 平台。
今年 3 月,「全球首位 AI 软件工程师」Devin 引爆了 AI 圈。与此前 AI 编程助手不同的是,Devin 并不只是辅助编程的角色,而是能够独立地、端到端地完成整个开发项目。
Devin 的出世让我们领略了大模型 Agent 的强大能力。很快,业界就出现了众多尝试复刻它的开源项目,其中 OpenDevin 脱颖而出,受到了人们最多的关注。
OpenDevin 是一个开发通过软件与世界互动的通用智能体的平台,其特点包括:
-
大模型 Agent、接口和环境之间交互的交互机制;
-
Agent 可用的沙盒操作系统 + Web 浏览器环境;
-
可创建和执行代码的接口;
-
多 Agent 支持;
-
评估框架。
目前,OpenDevin 的 GitHub 已经获得了超过 2.9 万 Star 量。
近日,OpenaDevin 团队发布了该工具的技术报告。

报告地址:https://arxiv.org/pdf/2407.16741
在技术报告中,OpenDevin 的作者,来自伊利诺伊大学香槟分校、卡耐基梅隆大学等机构的学者们详细介绍了 OpenDevin,这是一个社区驱动的平台,旨在开发通过软件与世界交互的通用和专业 AI Agent。
更重要的是,OpenDevin 不仅是一个概念框架,它还包括一个全面且可立即使用的 Agent、环境和评估实现。截至本报告发布时,OpenDevin 包含一个 Agent 中心,其中已实现 10 多个智能体,包括一个基于 CodeAct 架构实现的强大的通用智能体,并增加了用于 Web 浏览和代码编辑功能。用户与智能体的交互是通过聊天界面实现的,该界面可视化智能体当前操作并允许实时反馈。此外,评估框架目前支持 15 个基准,可使用它们来评估智能体性能。
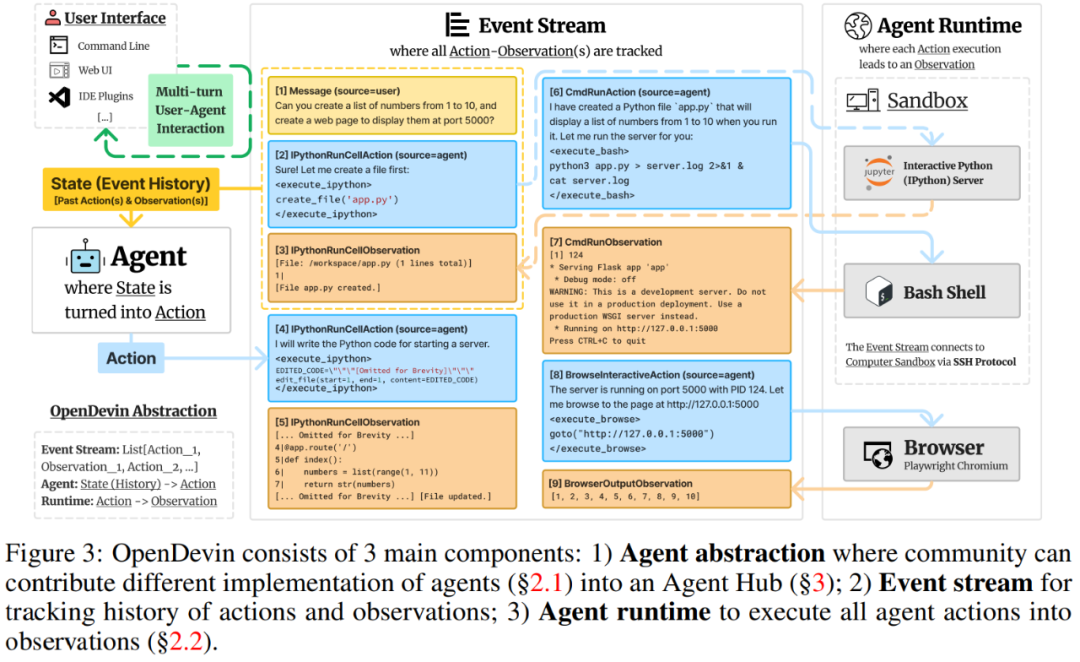
OpenDevin 架构
本文中,作者从以下几个方面描述 OpenDevin:(1)如何定义和实现智能体;(2)动作执行如何促进观察;(3)如何管理和扩展智能体常用的技能;(4)如何将多个智能体组合在一起以解决任务。
如何定义和实现智能体
智能体可以感知环境状态,并在解决用户指定的任务时生成要执行的操作。
状态和事件流。在 OpenDevin 中,状态是一种数据结构,它封装了智能体执行任务的所有相关信息。此状态的一个关键组成部分是事件流,是按照时间顺序收集过去的动作和观察。
动作。受 CodeAct 的启发,OpenDevin 通过一组核心的动作将智能体与环境连接起来。动作 IPythonRunCellAction 和 CmdRunAction 使智能体能够在沙盒环境(例如,安全隔离的 Linux 操作系统)内执行任意 Python 代码和 bash 命令。而 BrowserInteractiveAction 支持智能体与 Web 浏览器交互。
观察。观察描述了智能体观察到的环境变化。它可能由智能体的动作引起,也可能不是:它可以是 1) 用户提出的自然语言指令,2) 智能体先前动作的执行结果(例如,代码执行结果等)。
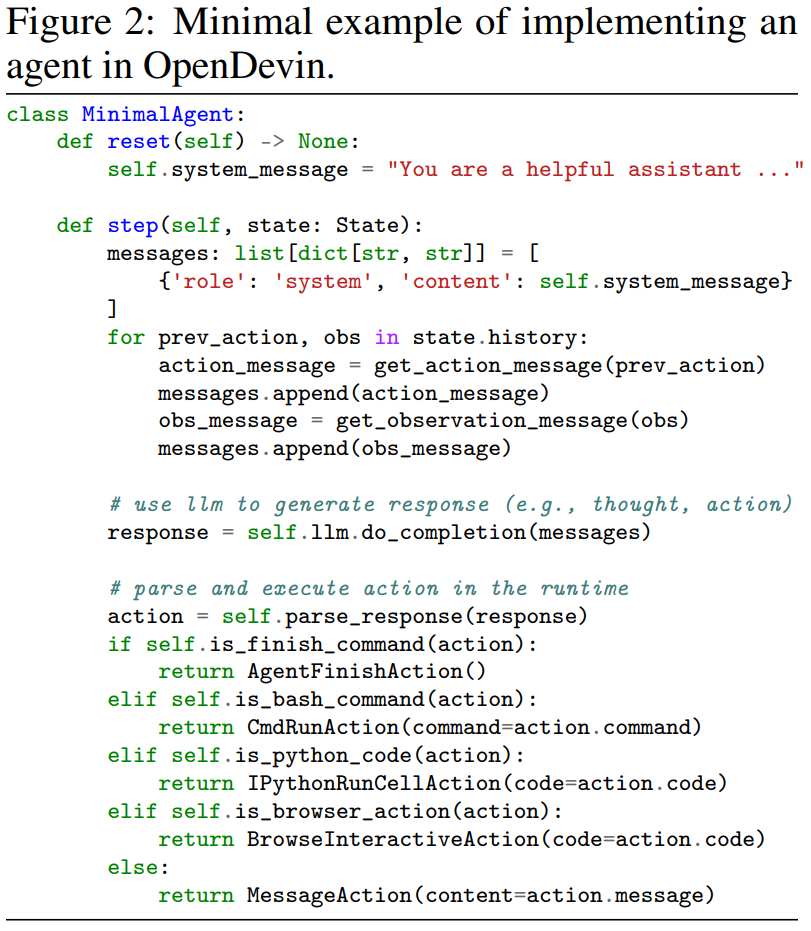
实现新的智能体。智能体设计简单但功能强大,从而允许用户轻松创建和定制用于各种任务的智能体。核心在于 step 函数,它将当前状态作为输入并根据智能体的逻辑生成适当的动作。图 2 显示了智能体抽象的简化示例代码。
观察动作执行结果
Agent Runtime 为智能体提供了与人类软件开发人员相当的动作空间,使 OpenDevin 能够处理各种软件开发和基于 Web 的任务,包括复杂的软件开发工作流程、数据分析项目、Web 浏览任务等。它允许智能体访问 bash 终端来运行代码和命令行工具,利用 Jupyter notebook 即时编写和执行代码,并与 Web 浏览器交互以执行基于 Web 的任务(例如,信息搜索)。
可扩展的智能体 – 计算机接口
作者构建了一个 AgentSkills 库,这是一个旨在增强智能体功能的工具箱,能够提供基本 bash 命令或 python 代码无法轻松获得的实用程序。
多智能体交互
OpenDevin 允许多个智能体进行交互。为了实现这一目标,作者使用了一种特殊的动作类型 AgentDelegateAction,它允许智能体将特定的子任务委托给另一个智能体。
评估
本节将 OpenDevin (以下实验结果中简写为 OD)与开源可复现的基线方法进行了比较。这 15 个基准涵盖软件工程、网页浏览等任务。
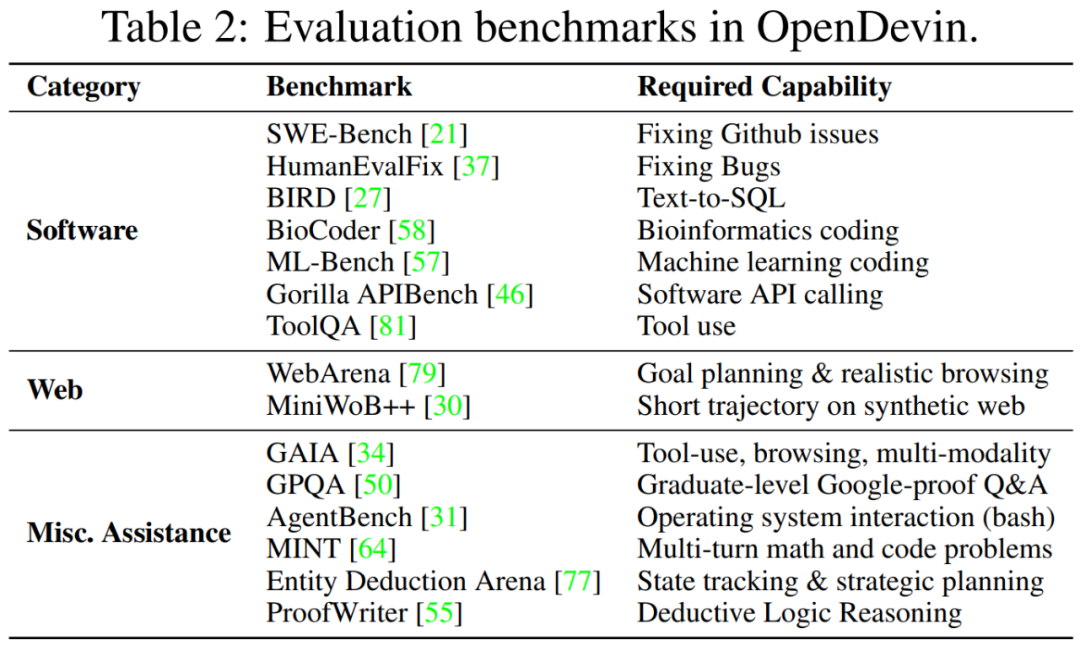
表 3 表明,虽然 OpenDevin 智能体可能无法在每个类别中都达到最佳性能,但其设计考虑了通用性。
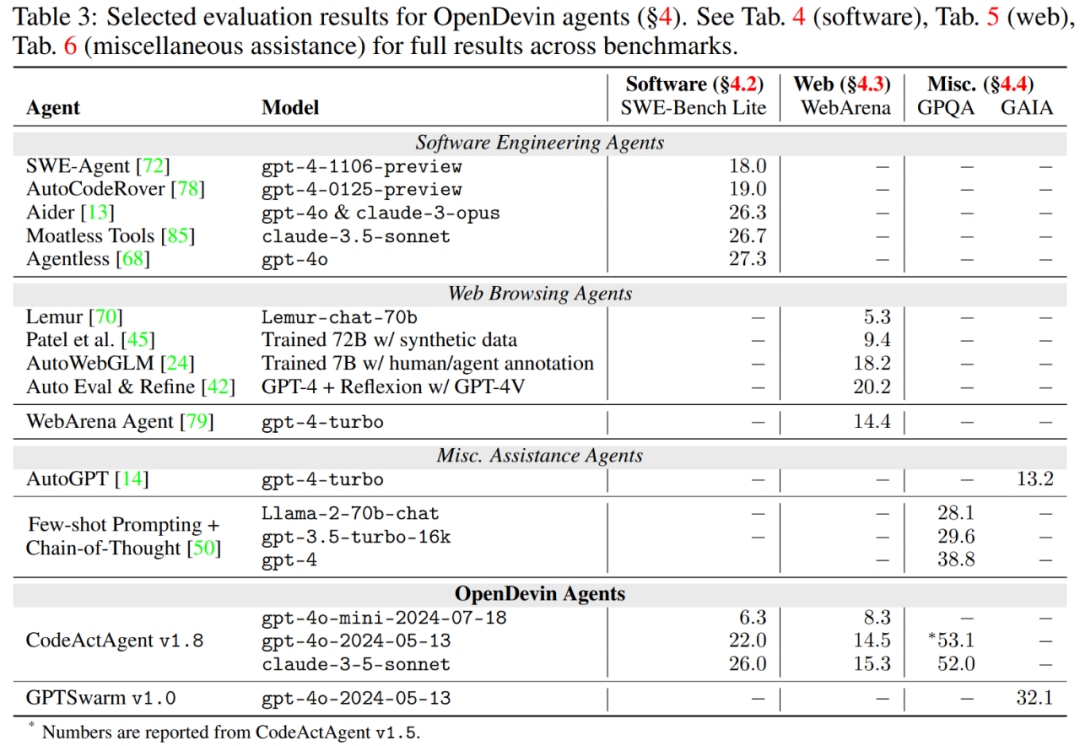
表 4 报告了智能体在软件工程基准上的结果。
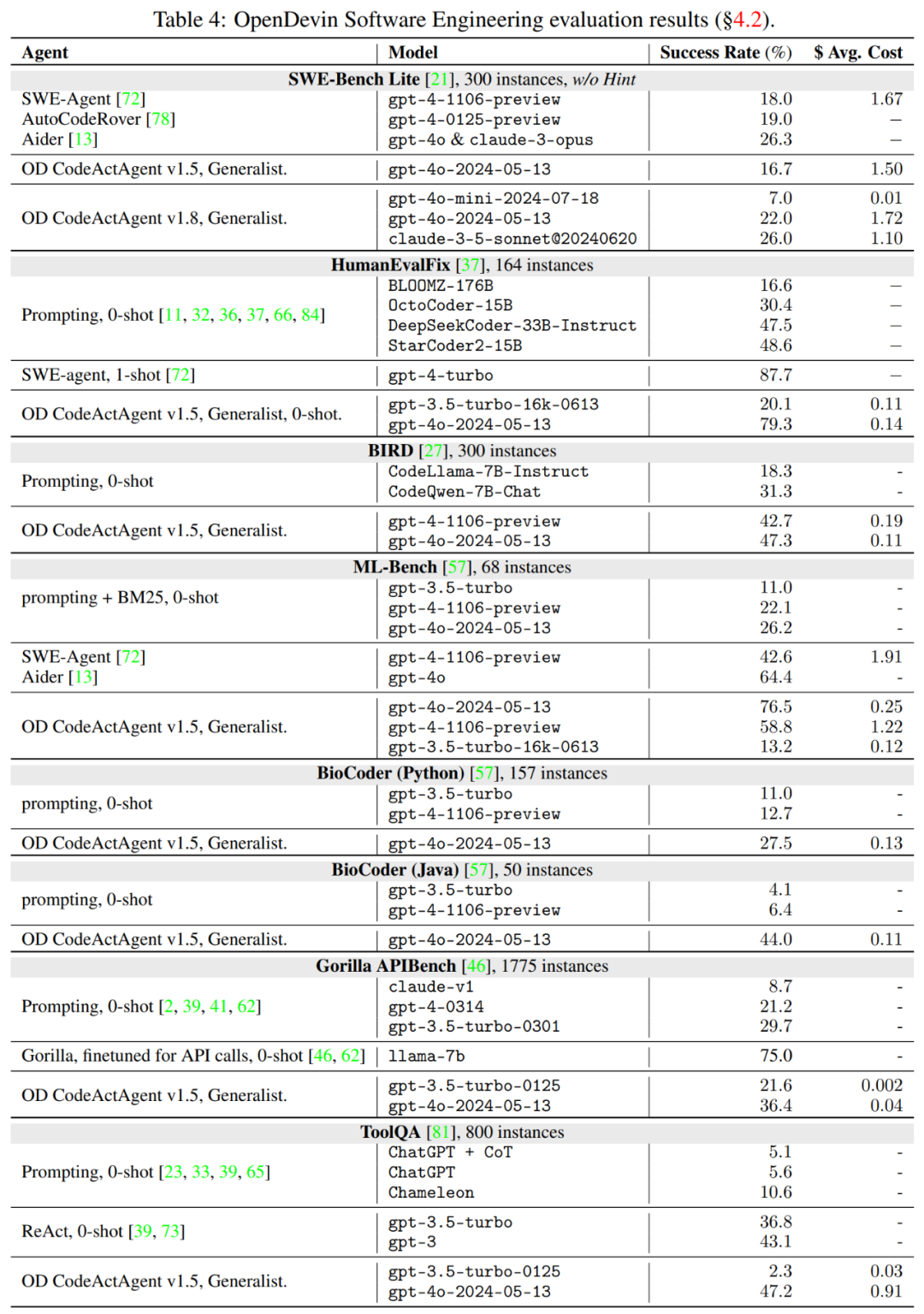
具体而言:
SWE-bench 旨在评估智能体解决 GitHub 问题的能力,如 bug 报告或功能请求。如表 4 所示,本文最新版本的 CodeActAgent v1.8 ,基于 claude-3.5-sonnet,与其他专门用于软件开发的开源智能体相比,解决问题率高达 26%。
HumanEvalFix。OpenDevin CodeActAgent 成功修复了 Python 拆分中 79.3% 的错误,明显优于所有非智能体方法,几乎是 StarCoder2-15B 性能的两倍。
基于 GPT-4o 的 OpenDevin 智能体在 ML-Bench 上实现了 76.47% 的最高成功率,优于 SWE-Agent(42.64%)。
Gorilla APIBench 考察智能体使用 API 的能力。使用 GPT-4o 的 OpenDevin 的成功率为 36.4%,优于未针对 API 调用进行专门微调的基线。
ToolQA 评估智能体使用外部工具的能力。与所有基线相比,采用 GPT-4o 的 OpenDevin 表现出最高的性能。智能体在与 CSV 和数据库工具使用相关的任务上表现更好,但在数学和计算器工具使用方面需要改进。
表 5 报告了网页浏览基准的评估结果。
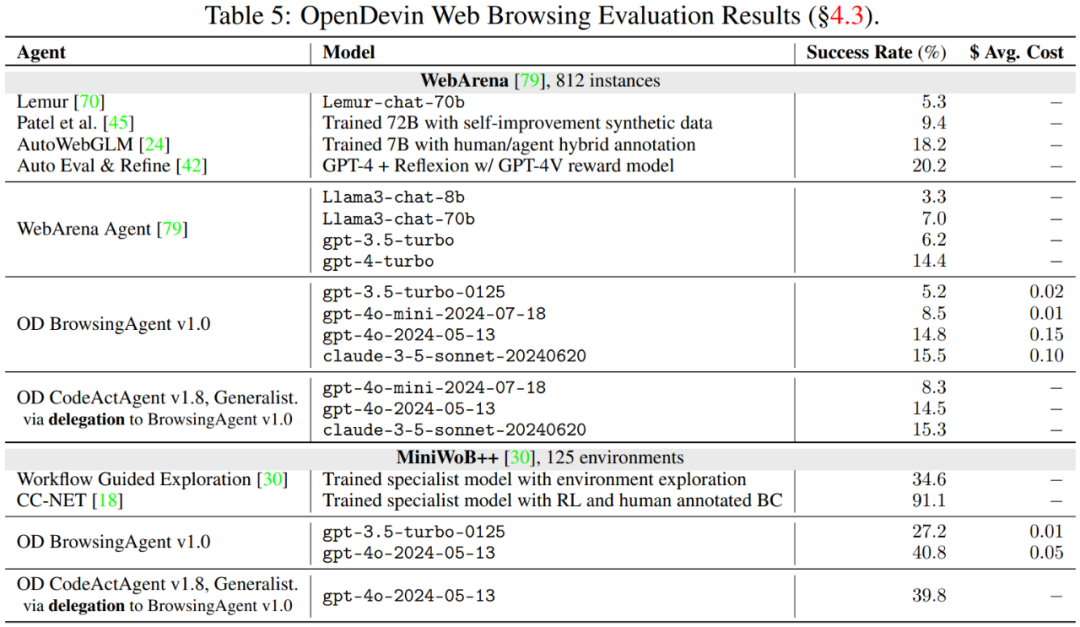
表 6 报告了各种辅助基准的结果。
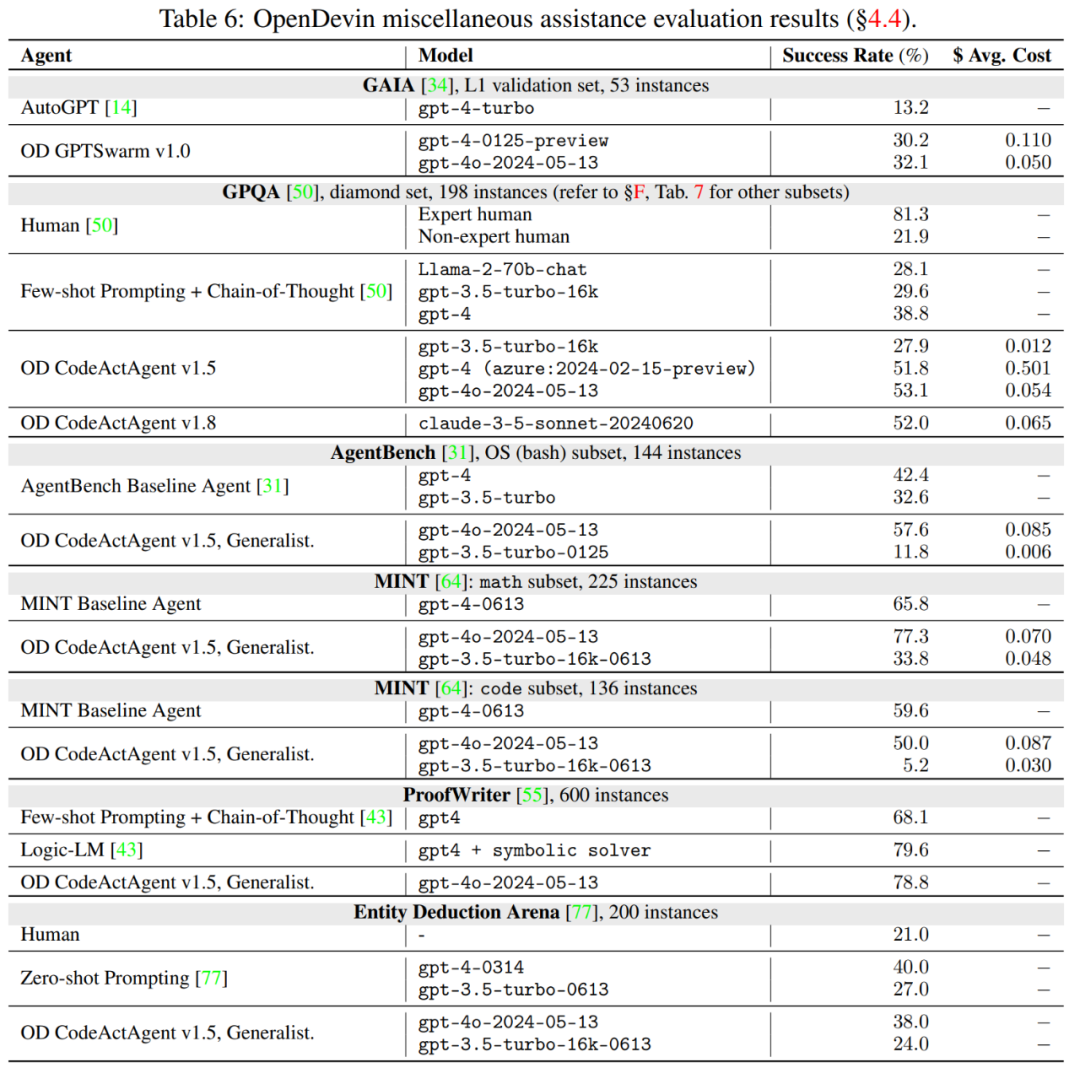
其中,GAIA 用于评估智能体解决一般任务的能力,结果显示,智能体在 GAIA 上取得了 32.1 分,比原来的 AutoGPT 有了明显的提高。
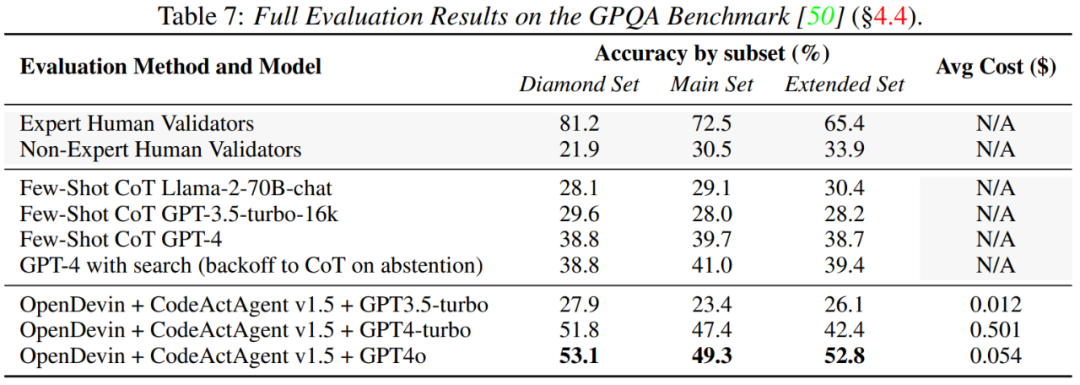
GPQA 用于评估智能体在解决具有挑战性的研究生水平问题时协调使用工具的能力。结果如表 6、7 所示,OpenDevin 集成了支持多种工具使用以及 web 搜索的功能,使得智能体能够更好地解决复杂的多步骤问题。